BGP
If you are unfamiliar with BGP and the terms used when talking about BGP, you might want to check out the RFC 4271 which has great definitions of the terms.
I will go through how BGP works and address some of its limitations. To do this, I will start with the following topology:
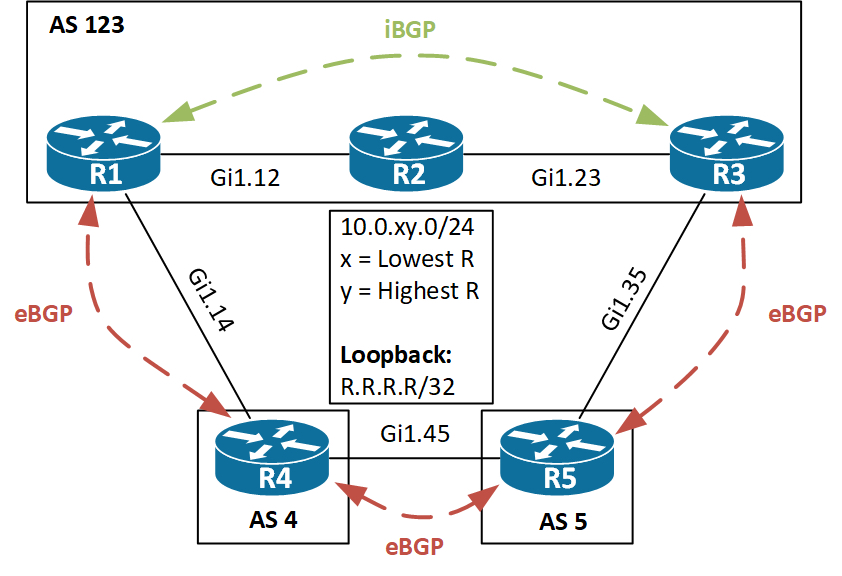
At first it might look confusing, but this is really a very simplified view of how a company could be connected to the Internet. The company is seen in the top using AS 123 and the ISPs at the bottom with AS 4 and AS 5. I have basic IP addressing configured between the routers.
Packets
BGP runs on top of TCP and uses port 179. To get up and running BGP has these messages:
- OPEN
- KEEPALIVE
- UPDATE
- NOTIFICATION
OPEN
This is the first message sent after a TCP session is established. Both peers send an OPEN message to each other containing:
- Version
- AS
- Hold time
- RID
- Optional parameters
Capture of the OPEN message:
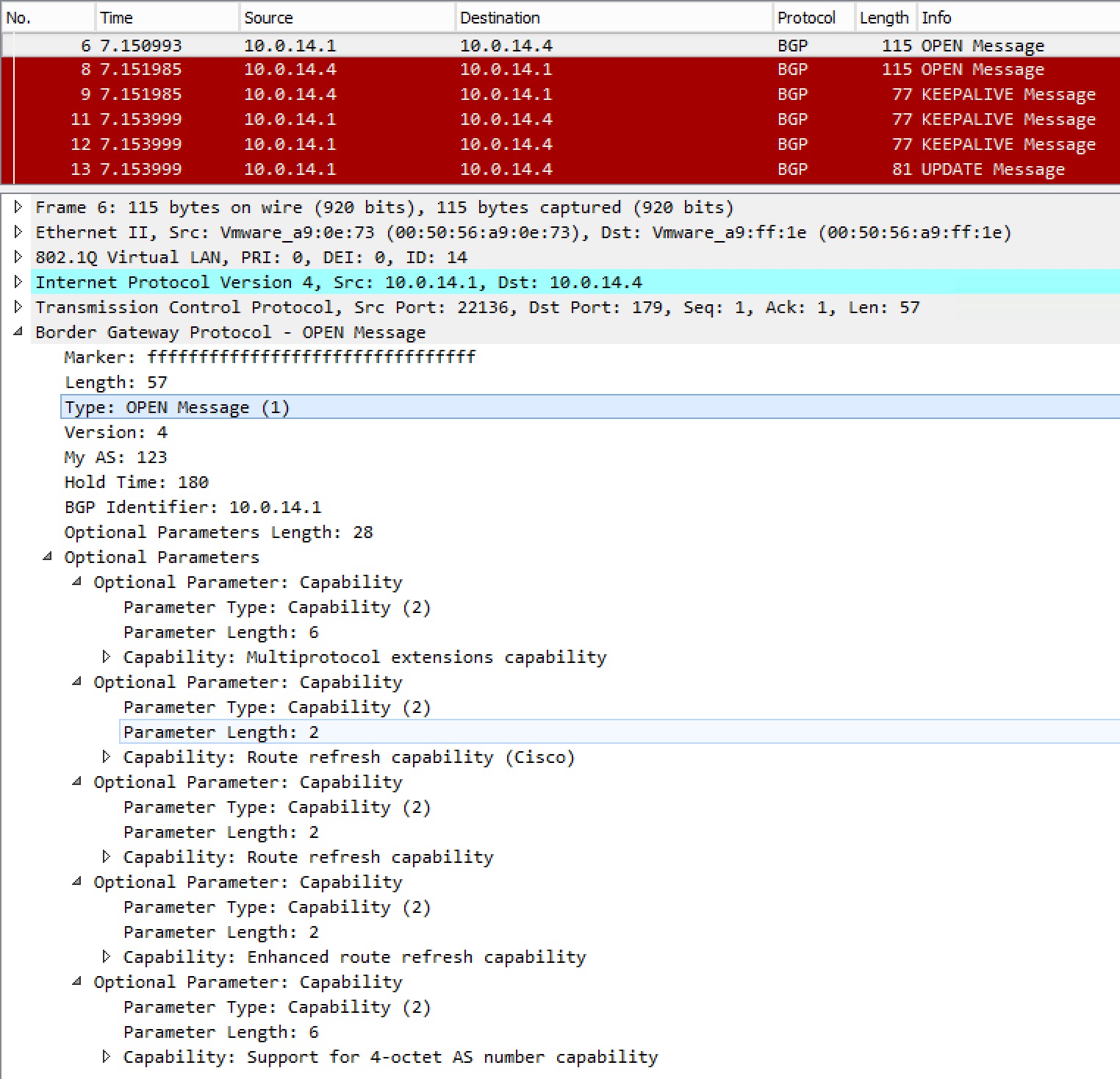
As predicted, we see what we expected in the OPEN message.
KEEPALIVE
The BGP KEEPALIVE message is used to ensure the hold timer does not expire letting the peer know that we are still alive. It keeps the session up.
A capture of the KEEPALIVE:
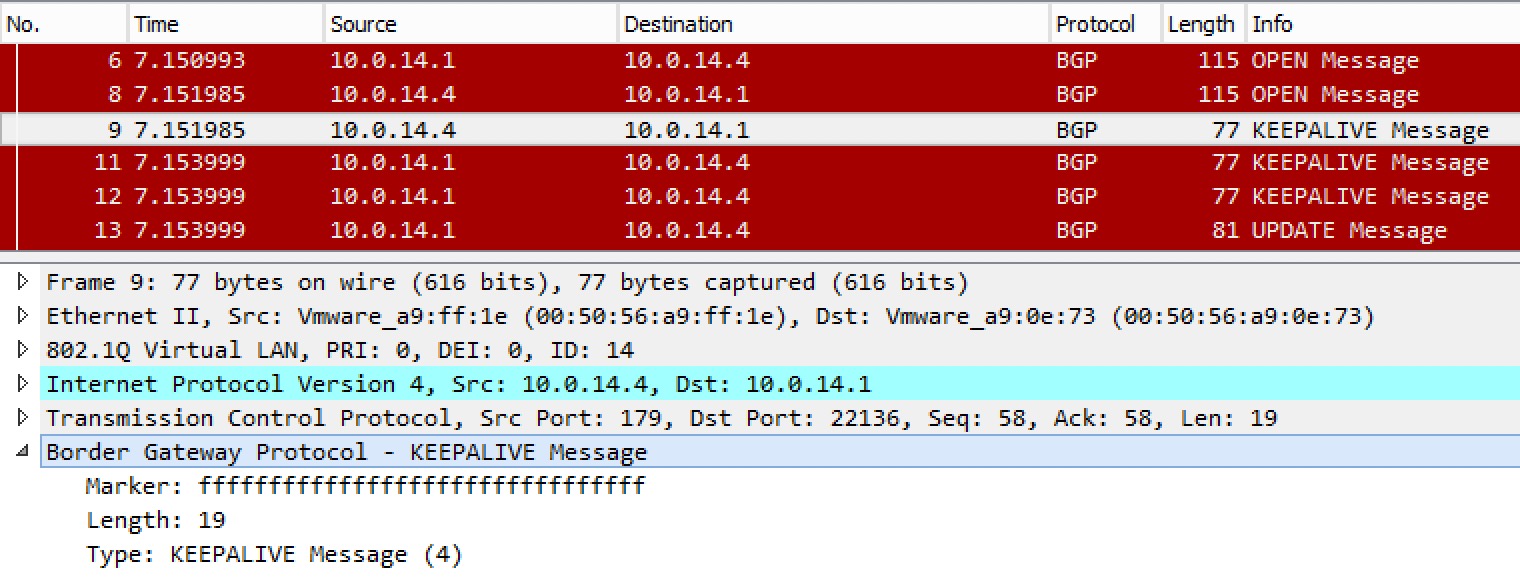
No much content, but enough to let the peer know we are still here.
UPDATE
UPDATE messages are used to exchange prefixes and withdraw prefixes. It also resets the hold timer on the peer receiving the UPDATE message.
A capture of a BGP UPDATE message of R1 advertising 123.123.123.0/24 to R4:

Notice how the prefix and PAs (Path Attributes) are separated. BGP groups prefixes that share the same PAs in a single update.
A capture of an UPDATE that does a withdraw of the prefix:
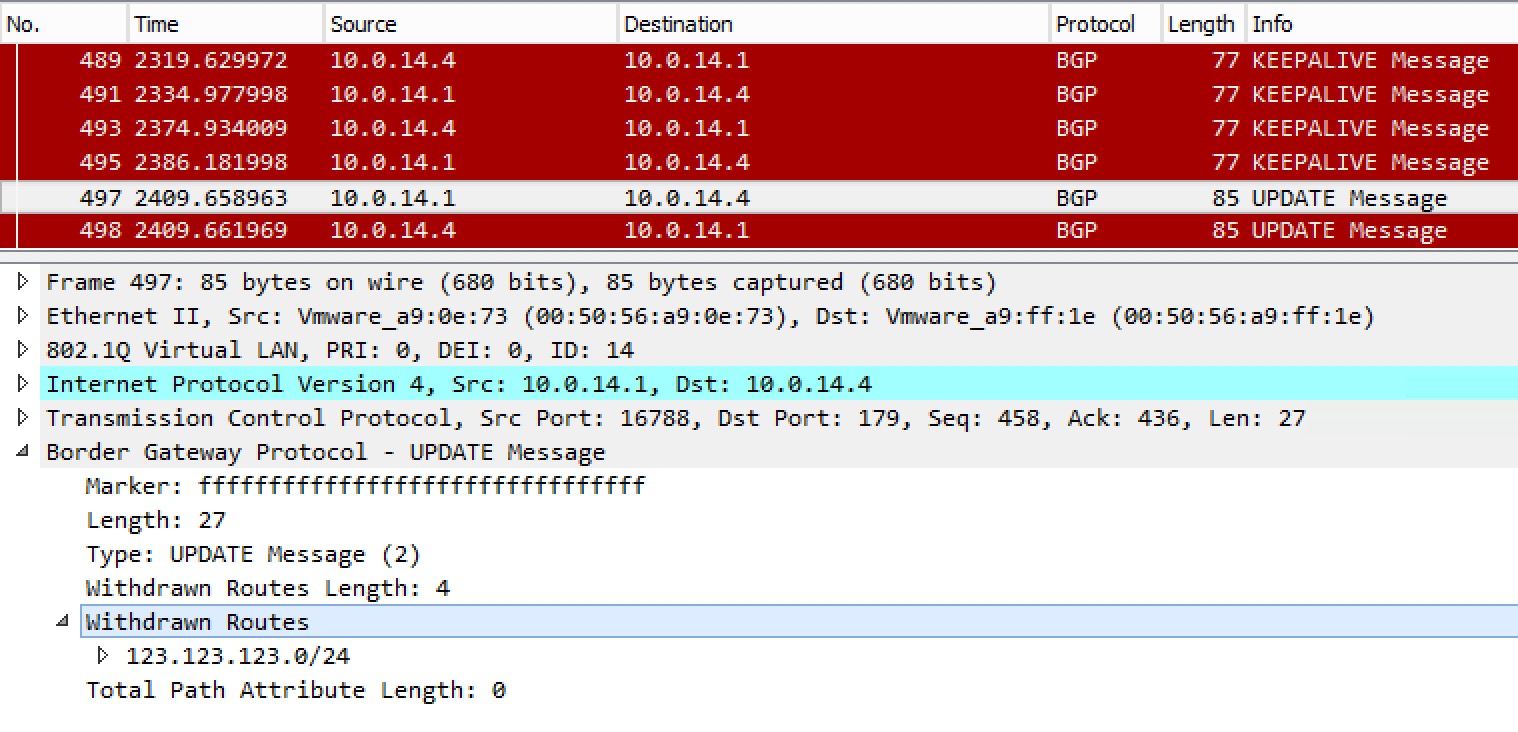
NOTIFICATION
A BGP Notification message means something went wrong. It results in the peering being torn down.
You can see a complete list of possible notification messages in the RFC under Section 4.5
Below is a capture of a BGP Notification message:
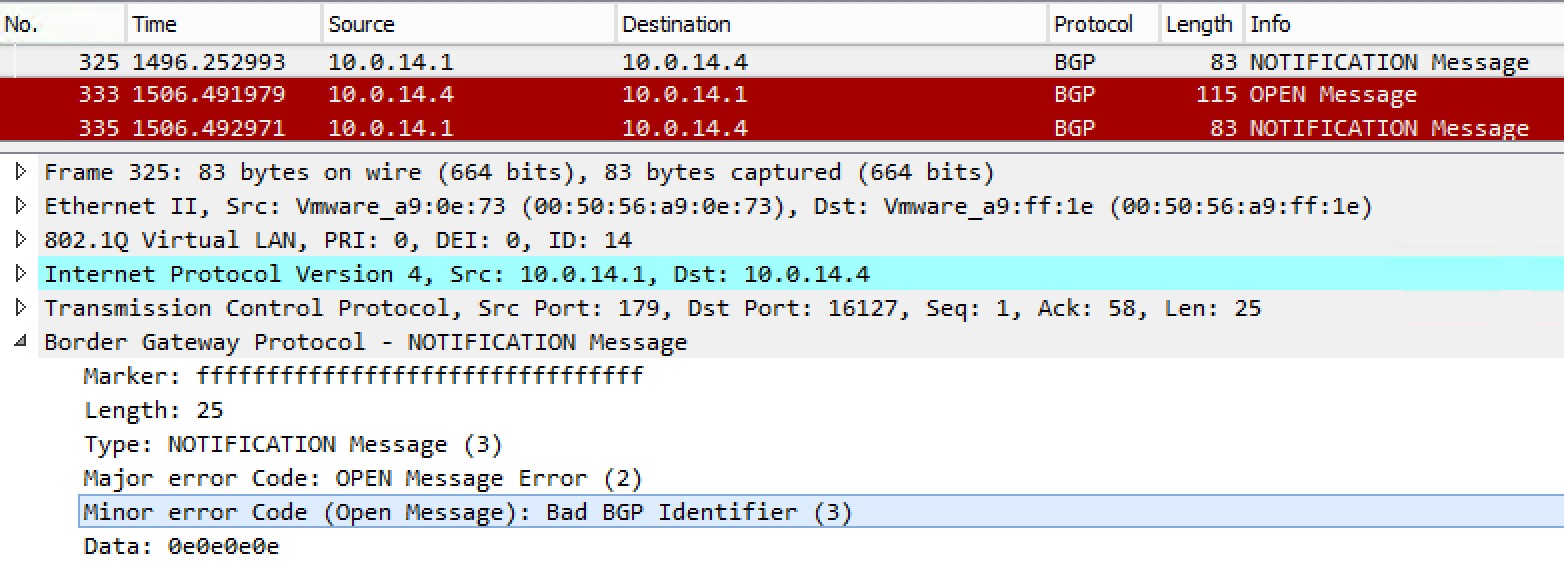
Here we see a notification telling the other peer that the BGP Identifier (Essentially the Router-ID) is bad (overlapping). The data reveals the router-id in hex, 0x0E = 14 (decimal). I had purposefully configured the bgp router-id to be 14.14.14.14 on both R1 and R4 to demonstrate this.
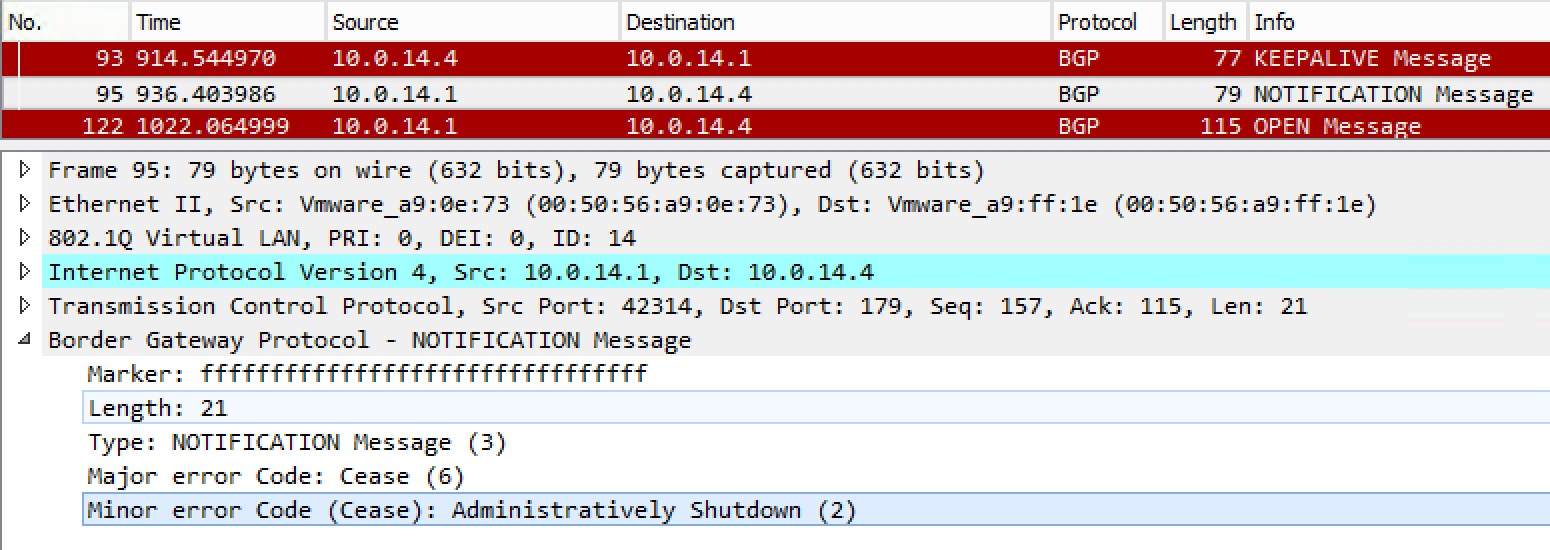
A notification is also sent when you shutdown a peer:
eBGP
BGP is meant to be run between autonomous systems and between directly connected routers. This is why the TTL for eBGP is set to 1. Also the NH (Next Hop) is changed to the source of the updates when prefixes are exchanged between different ASes.
! R1 peering with R4: R1(config)#router bgp 123 R1(config-router)#nei 10.0.14.4 remote-as 4 ! R4 peering with R1: R4(config)#router bgp 4 R4(config-router)#nei 10.0.14.1 remote-as 123
Above we see an eBGP peering configuration between R1 and R4. The peering is considered eBGP because it is done between to different autonomous systems, AS 123 and AS 4.
By default no prefixes are advertised in BGP. So no prefixes are exchanged between R1 and R4 at this moment. We can however verify the peering:
! R1 peering verification: R1# %BGP-5-ADJCHANGE: neighbor 10.0.14.4 Up R1#sh bgp ipv4 unicast summary BGP router identifier 10.0.14.1, local AS number 123 BGP table version is 1, main routing table version 1 Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd 10.0.14.4 4 4 8 8 1 0 0 00:05:00 0 R1#
When a peer comes up we see a log for it letting us know that a new peering has been formed. We can also view the peerings and their state using the show bgp summary command.
What if we want to allow a peering between Loopback interfaces or over multiple hops – say through a firewall? We have a couple of options here. Let’s have a look at them:
ebgp-multihop
eBGP sets the TTL to 1 allowing only directly connected neighbors to form a peering. But you might have a scenario where you want to either peer using the loopback interfaces or just over multiple hops. The ebgp-multihop feature can change the TTL. By default, with no options, the TTL is set to 255 when enabling ebgp-multihop on a neighbor.
! R1 peering with R4 using Loopbacks: R1(config)#router bgp 123 R1(config-router)#neighbor 4.4.4.4 remote-as 4 R1(config-router)#neighbor 4.4.4.4 update-source lo0
R4 has been configured the same way using its update-source as Lo0. If we examine the neighbor on R1, we see that BGP won’t even try to establish a peering with R4 (and R4 with R1), because it knows the neighbor is not directly connected:
! R1 not directly connected to R4: R1#sh bgp nei 4.4.4.4 | in External External BGP neighbor not directly connected. R1#
Let’s configure the ebgp-multihop:
! R1 ebgp-multihop configuration: R1(config)#router bgp 123 R1(config-router)#neighbor 4.4.4.4 ebgp-multihop
We can verify the neighbor on R1 again:
! R1 verify ebgp-multihop: R1#sh bgp nei 4.4.4.4 | in External External BGP neighbor may be up to 255 hops away. R1#
But R1 still cannot establish a peering with R4. This is because R4 also must be configured for ebgp-multihop. As soon as R4 is also configured, the peering will come up.
Note! If you specify ebgp-multihop 1 and want to peer using the loopback interfaces between two directly connected routers, you must also configure the disable-connected-check feature. I’ll explain why in the ttl-security hops section.
ttl-security hops
Another, and more secure, way of changing the TTL of an eBGP peering is to configure the ttl-security hops feature. It is also knows as GTSM (Generalized TTL Security Mechanism). You can find it in RFC 5082. In contrast to the ebgp-multihop the ttl-security hops actually lowers the TTL from 255 minus the number of hops you configured with the feature. This ensures that an attacker cannot change his TTL to a calculated value thereby “hitting” the BGP router with spoofed BGP packets and possibly executing a DoS attack. Due to this feature being the opposite of ebgp-multihop, they are mutual exclusive, meaning you cannot have both configured for a neighbor at the same time. You can however mix them as long as they are configured on different routers – not on the same router for the same neighbor!
! R1 ttl-security hops configuration: R1(config)#router bgp 123 R1(config-router)#neighbor 4.4.4.4 ttl-security hops 2 R1(config-router)#
We can verify the feature on R1:
! R1 ttl-security hops verification: R1#sh bgp nei 4.4.4.4 | in External External BGP neighbor may be up to 2 hops away. R1#
And if we look at a capture taken on R4s Gi1.14 inbound, we see this:
Many documents suggest that the router decrements the TTL as the packet comes in to the router. This is not true. The router actually only decrements the TTL before routing it to an egress interface – like a Loopback interface. The only reason why the ttl-security hops must be set to 2 for this to work is that the router still has the directly connected check enabled for eBGP peerings, meaning that the router will simply not initiate a session with a peer if the neighbor address is not reachable via a connected interface. Nothing more! This means that for the above configuration of setting the hop count to 2 is not necessary. If you configure the disable-connected-check along with ttl-security hops 1 it will work.
disable-connected-check
To overcome the directly connected issue when peering over two hops, you can tell bgp to disable this directly connected check. The TTL is still set to 1 outbound, but the minimum TTL is lowered to 0:
! R1 disable-connected-check configuration: R1(config)#router bgp 123 R1(config-router)#neighbor 4.4.4.4 disable-connected-check R1(config-router)#
! R1 verify disable-connected-check: R1#sh bgp nei 4.4.4.4 | in TTL Connection is ECN Disabled, Mininum incoming TTL 0, Outgoing TTL 1 R1#
This is why we can still establish a peering between the loopback interfaces of R1 and R4. If you want to peer over more than two hops, you must use the disable connected check with
Path Attributes
BGP has four categories of PAs (Path Atrributes):
- Well-known Mandatory
- Well-known Discretionary
- Optional transitive
- Optional non-transitive
Every BGP implementation must support the well-known types of PAs. Some of the well-known attributes are mandatory, meaning that they must be included in an update. The well-known discretionary attributes may � or may not be included in an update.
Finally the optional PAs are not required or expected to be supported by all BGP implementations. That being said, the optional transitive PAs should be accepted. If they are, they must be passed along in updates. Unrecognised optional non-transitive attributes must be quietly ignored and not passed along to any BGP peers.
The PAs themselves are listed below for reference and usage.
ORIGIN
Well-known mandatory attribute.
Generated by the speaker that originates the NLRI.
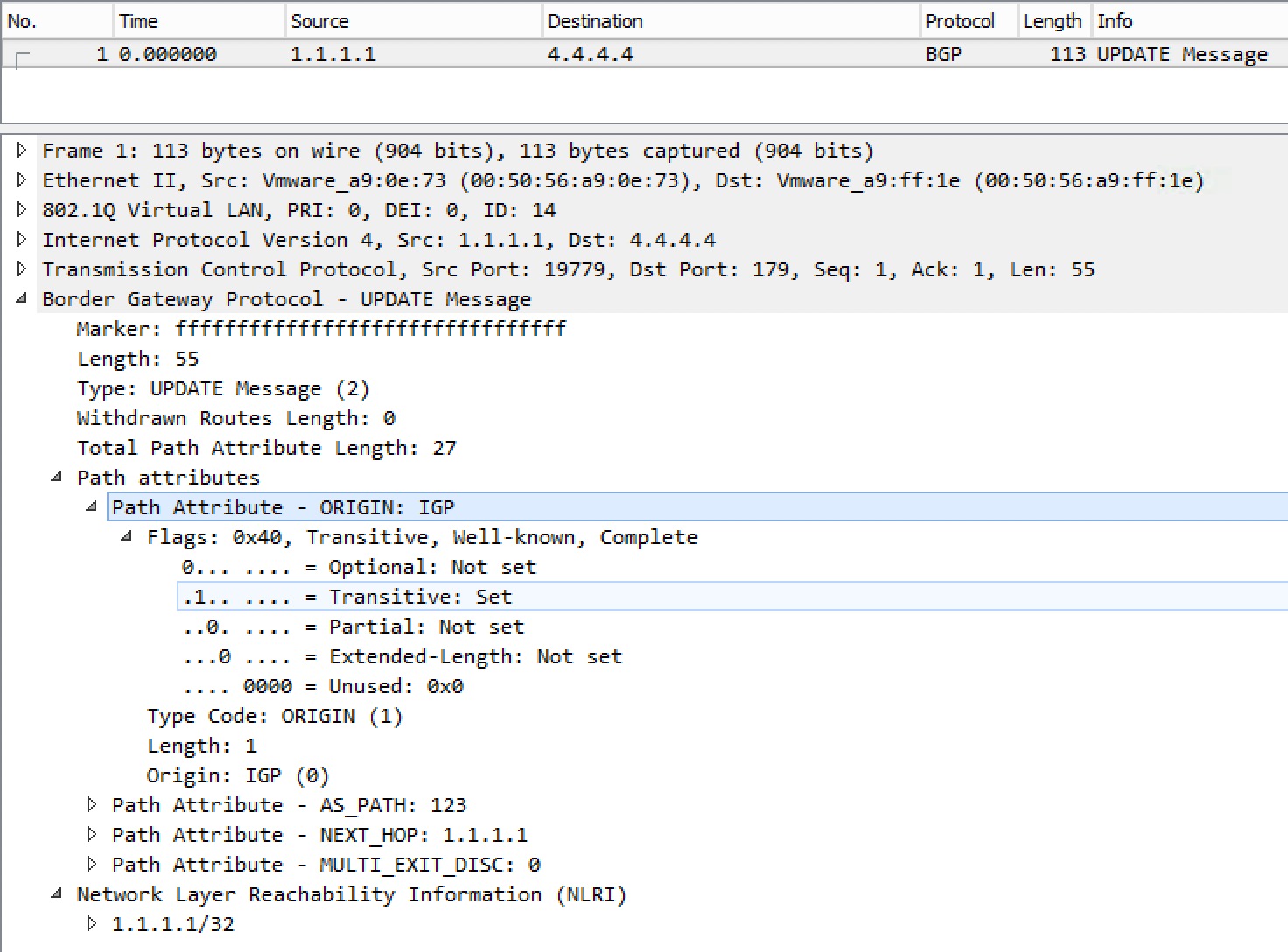
Here we see an update from R1 containing a single prefix with the ORIGIN PA set to IGP. It has also been flagged as transitive.
AS_PATH
Well-known mandatory attribute.
Autonomous systems the NLRI has passed through. Can be represented via an AS_SET or AS_SEQUENCE list.
The AS_SET is an unordered list of ASes. You typically see this for an aggregate that has the as-set keyword configured.
The AS_SEQUENCE is an ordered list of the ASes. This is what is normally used.
For BGP confederations these lists also exist. They are called AS_CONFED_SET and AS_CONFED_SEQUENCE.
The AS is prepended (added to the leftmost position of the AS_PATH) before sending the update to an eBGP peer. When sending an update to an iBGP peer, the router does not prepend its own AS.
NEXT_HOP
Well-known mandatory attribute.
Defines the next hop IP that should be used to reach the destinations listed in the update message.
If the update is not locally originated and the update is sent to an iBGP peer, the next-hop is not changed unless you configured it to do so. If the router originated the update, the next-hop is set to the update-source of the peering.
For eBGP updates the next-hop is set to to update-source of the speaker. It can also be set to a third-party next-hop, if for example the prefix was received from an iBGP peer and both the iBGP peer and the eBGP peer share a common subnet.
MULTI_EXIT_DISC
Optional non-transitive attribute.
Used on inter-AS links to discriminate among multiple exit or entry points to the same neighboring AS.
The value is called a metric. It must not be propagated to neighboring ASes.

LOCAL_PREF
Well-known discretionary attribute.
Used within an AS to set a preferable exit point. It must not be advertised to eBGP peers.
ATOMIC_AGGREGATE
Well-known discretionary attribute.
Set by the router doing the aggregation.
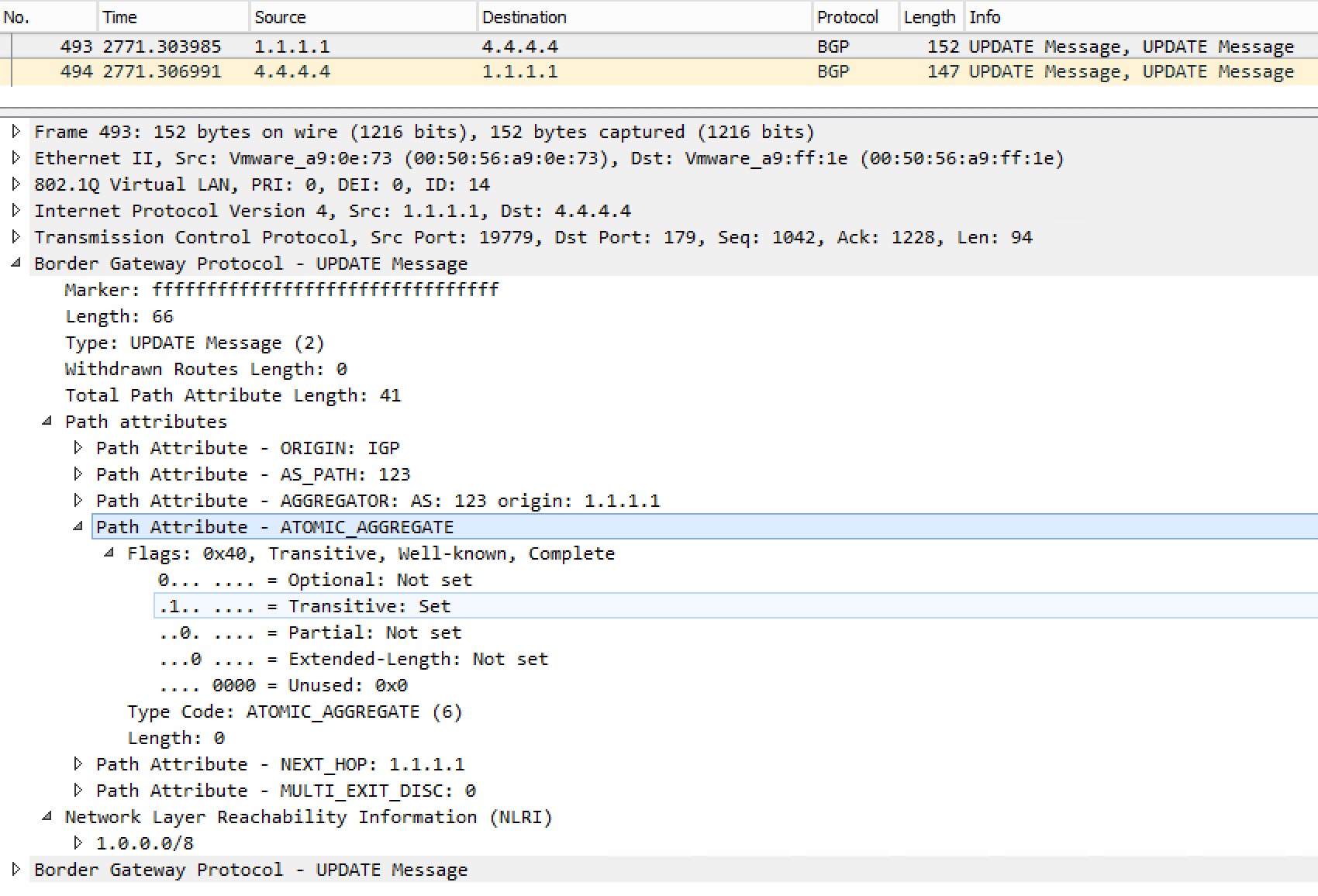
AGGREGATOR
Optional transitive attribute.
Created by the router doing the aggregation and contains the AS and IP (RID) of the speaker.
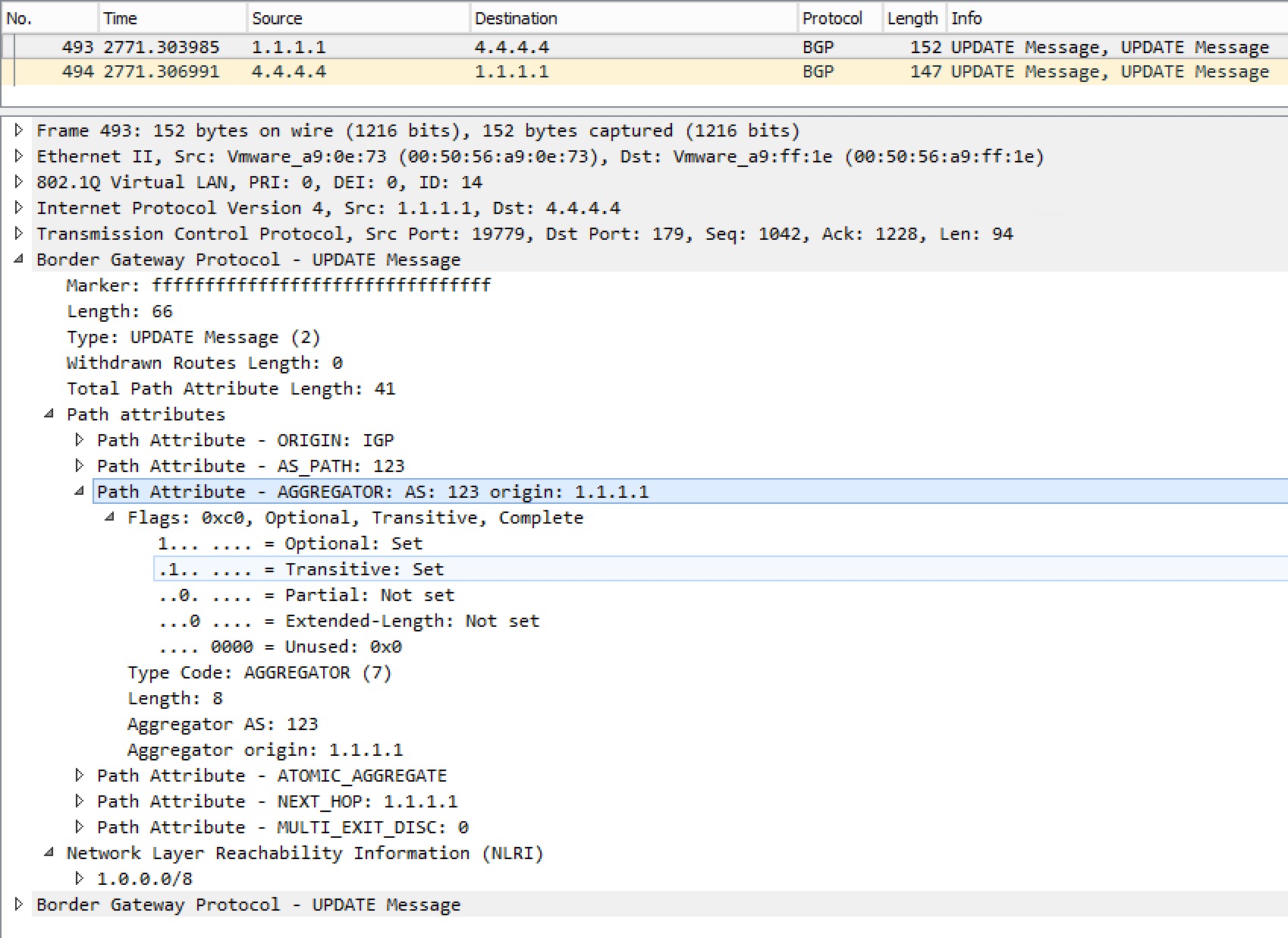
COMMUNITY
Optional transitive attribute.
Works like a tag in BGP.
ORIGINATOR_ID
Optional non-transitive attribute.
RID of the originating router within a local AS. Used for loop prevention when using RRs (Route Reflectors).
CLUSTER_LIST
Optional non-transitive attribute.
Used for loop prevention when using RRs. Set by the RR when reflecting routes from clients to non-clients. The value of the list is the Cluster ID that is appended to the NLRI by every RR cluster it goes through.
Path Selection Algorithm
BGP has a lot of tiebreakers between the PAs for it to determine which path is best for a particular prefix. Before BGP even considers a path as candidate to be used, it must be valid (meaning not suppressed, rib-failure, damped) and have a reachable next-hop IP address.
- Prefer the path with the highest WEIGHT
- Prefer the path with the highest LOCAL_PREF
- Prefer the path that was Locally originated.
- Prefer the path with the shortest AS_PATH
- Prefer the path with the lowest ORIGIN type (IGP < Incomplete < EGP)
- Prefer the path with the lowest MED (MULTI_EXIT_DISC)
- Prefer the path with the lowest Neighbor type (eBGP < iBGP paths)
- Prefer the path the the lowest IGP metric to the next-hop
- Determine if� Multiple� paths require installation into the routing table.
- Prefer the Oldest path (one that was received first) when both paths are external
- Prefer the path from the BGP router with the lowest Router-ID
- Prefer the path with the minimum� Cluster list� length
- Prefer the path that comes from the lowest� neighbor� Address
I always remember the above steps using a� mnemonic. If you take the first letter of the words written in bold from the above list, you end up with:� WLLA OMNI MORCA
Somehow this is easy for me to remember. You might have another way of doing it.
Add-Path
I’ll use this 5 router topology:

R5 injects 5.5.5.5/32 and does some AS_PATH prepending, too. The idea is to have R2 advertise, the RR, advertise to R1 both paths of 5.5.5.5/32 that it learns from R3 and R4. R1 should the ideally install both paths and do multipath which is� NOT� Add-Path related, but just something I thought would be nice to have once it knew both paths and had full visibility.
BGP only advertises the best route it has. In a topology where you have RRs, the path diversity is lost which can lead to sub-optimal routing. BGP Add-Path offers a generic way of advertising multiple paths for the same prefix.
The advertisement of a prefix replaces the previous advertisement of that prefix. This is called an implicit withdraw. Add-Path mitigates this behavior by using a path identifier to each path in the NLRI. This is analogous to RD in VPNs. Path IDs are unique to a peering session and are generated for each network.
Three steps are required to configure BGP Add-Path:
Activate the Add-Path capability which is negotiated during session establishment. To do this, specify whether you want to be able to send, receive, or both send and receive additional paths. Either per-afi or per-neighbor:
bgp additional-paths {send [receive] | receive}neighbor additional-paths {send [receive] | receive}
Select a set or sets of candidate paths for advertisement
bgp additional-paths select
Advertise to a neighbor the set or sets of additional paths that were selected during step 2.
neighbor advertise additional-paths
Let’s have a look at how this looks in wireshark. First the session establishment, meaning the OPEN message:

Here we clearly see the Support for Additional Paths capability. And this router does “send” for IPv4 Unicast.
Now let’s see how an update looks:
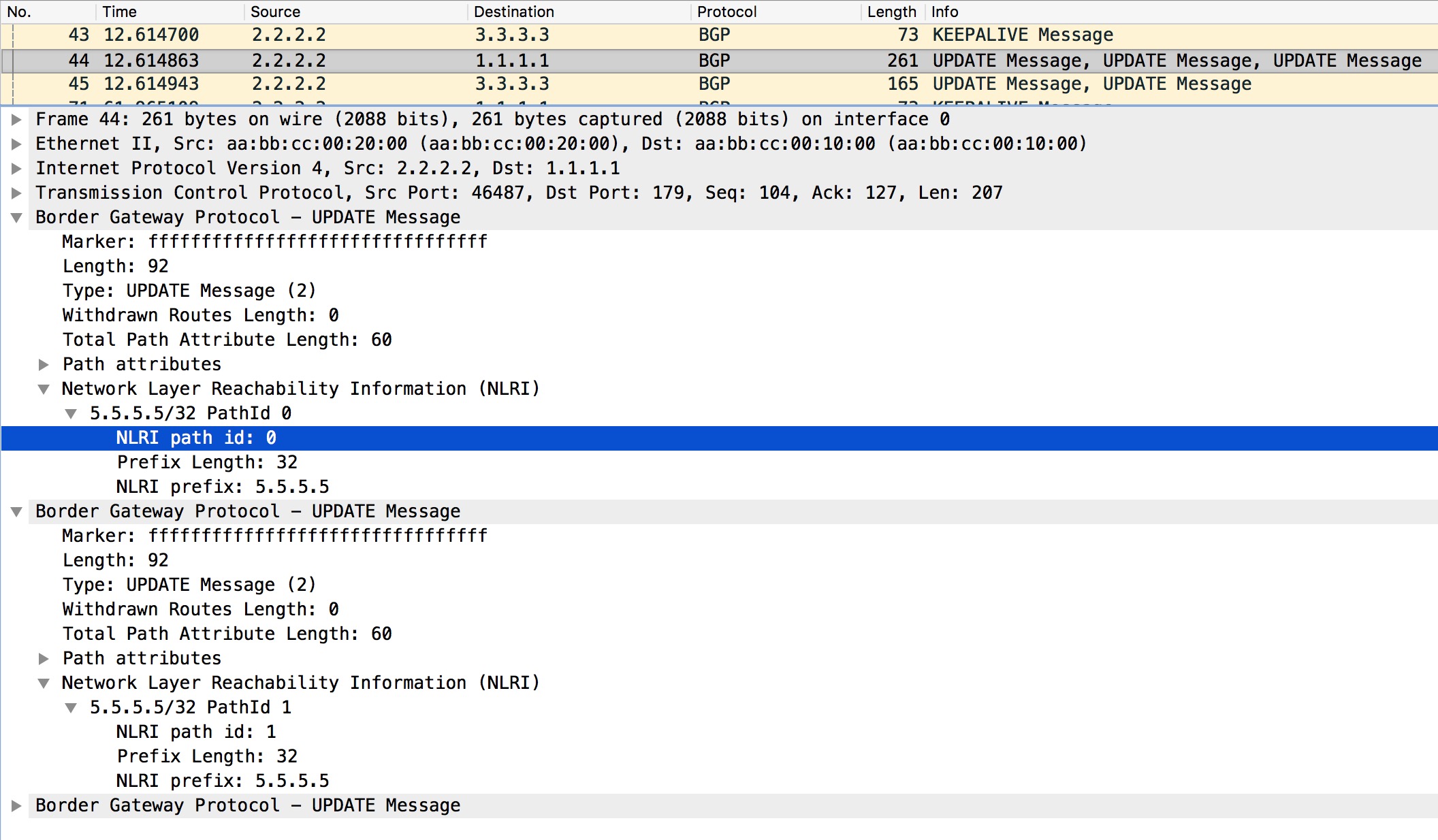
The path identifier is listed under the NLRI as expected. This was to hinder the implicit withdrawal.
If we look at R1’s BGP table:
! R1 BGP table:
R1#sh bgp 5.5.5.5/32
BGP routing table entry for 5.5.5.5/32, version 14
Paths: (2 available, best #1, table default)
Multipath: iBGP
Not advertised to any peer
Refresh Epoch 5
345 653535 655353 5
3.3.3.3 (metric 11) from 2.2.2.2 (2.2.2.2)
Origin IGP, metric 0, localpref 100, valid, internal, best
Originator: 3.3.3.3, Cluster list: 2.2.2.2
rx pathid: 0x1, tx pathid: 0x0
Refresh Epoch 5
345 654545 655454 5
4.4.4.4 (metric 21) from 2.2.2.2 (2.2.2.2)
Origin IGP, metric 0, localpref 100, valid, internal
Originator: 4.4.4.4, Cluster list: 2.2.2.2
rx pathid: 0x0, tx pathid: 0
R1#
We see that R1 receives both paths from R2 thanks to BGP Add-Path. Multipath: iBGP is also seen which enables the router to install multiple routes of a prefix when applicable! Right now� NO� multipath is seen on this prefix, because the best path selection for multipath is not satisfied! If we count the ASes in the AS_PATH we see an equal number (4 ASes) for both paths. Also all the other attributes are equal. Except for the IGP to next-hop which is 11 for 3.3.3.3 and 21 for 4.4.4.4. Ok, so we can configure BGP to ignore this step of the best path selection process. Let’s do that:
! R1 BGP disable IGP metric to NH: R1(config)#router bgp 1234 R1(config-router)#address-family ipv4 R1(config-router-af)#bgp bestpath igp-metric ignore R1(config-router-af)#
Let’s verify again:
! R1 BGP table:
R1#sh bgp 5.5.5.5/32
BGP routing table entry for 5.5.5.5/32, version 18
BGP Bestpath: igpmetric-ignore
Paths: (2 available, best #1, table default)
Multipath: iBGP
Not advertised to any peer
Refresh Epoch 5
345 653535 655353 5
3.3.3.3 (metric 11) from 2.2.2.2 (2.2.2.2)
Origin IGP, metric 0, localpref 100, valid, internal, best
Originator: 3.3.3.3, Cluster list: 2.2.2.2
rx pathid: 0x1, tx pathid: 0x0
Refresh Epoch 5
345 654545 655454 5
4.4.4.4 (metric 21) from 2.2.2.2 (2.2.2.2)
Origin IGP, metric 0, localpref 100, valid, internal
Originator: 4.4.4.4, Cluster list: 2.2.2.2
rx pathid: 0x0, tx pathid: 0
R1#
Still no multipath! Why is that!? Everything is equal and we’re ignoring IGP metric to next-hop so the paths should be eligible to be considered for multipath. They are not, because the AS_PATH’s content is different! BGP will only consider paths for multipath when the AS_PATHs are� exactly� the same! We have to relax this strict check with a hidden command:
! R1 BGP as-path multipath-relax: R1(config)#router bgp 1234 R1(config-router)#bgp bestpath as-path multipath-relax
And we should verify again:
! R1 BGP table:
R1#sh bgp 5.5.5.5/32
BGP routing table entry for 5.5.5.5/32, version 19
BGP Bestpath: igpmetric-ignore
Paths: (2 available, best #1, table default)
Multipath: iBGP
Not advertised to any peer
Refresh Epoch 5
345 653535 655353 5
3.3.3.3 (metric 11) from 2.2.2.2 (2.2.2.2)
Origin IGP, metric 0, localpref 100, valid, internal, multipath, best
Originator: 3.3.3.3, Cluster list: 2.2.2.2
rx pathid: 0x1, tx pathid: 0x0
Refresh Epoch 5
345 654545 655454 5
4.4.4.4 (metric 21) from 2.2.2.2 (2.2.2.2)
Origin IGP, metric 0, localpref 100, valid, internal, multipath(oldest)
Originator: 4.4.4.4, Cluster list: 2.2.2.2
rx pathid: 0x0, tx pathid: 0
R1#
Success! We finally managed to get the multipath feature working. Now BGP should install both paths in the routing table, too:
! R1 routing table for 5.5.5.5:
R1#sh ip route 5.5.5.5
Routing entry for 5.5.5.5/32
Known via "bgp 1234", distance 200, metric 0
Tag 45, type internal
Last update from 4.4.4.4 00:01:52 ago
Routing Descriptor Blocks:
4.4.4.4, from 2.2.2.2, 00:01:52 ago
Route metric is 0, traffic share count is 1
AS Hops 4
Route tag 45
MPLS label: none
* 3.3.3.3, from 2.2.2.2, 00:01:52 ago
Route metric is 0, traffic share count is 1
AS Hops 4
Route tag 45
MPLS label: none
R1#