Classical Enterprise LAN Design - Part I
Table of Contents
Many enterprises still have what is considered a classical network. This post deals with one such design. Focus is on highlighting the reasons why a network is built this way and reveal its shortcomings. Lastly some suggestions on how to optimize the logical design are shown.
Topology
Below topology is the starting point. Some choices have been taken as described in the green boxes.
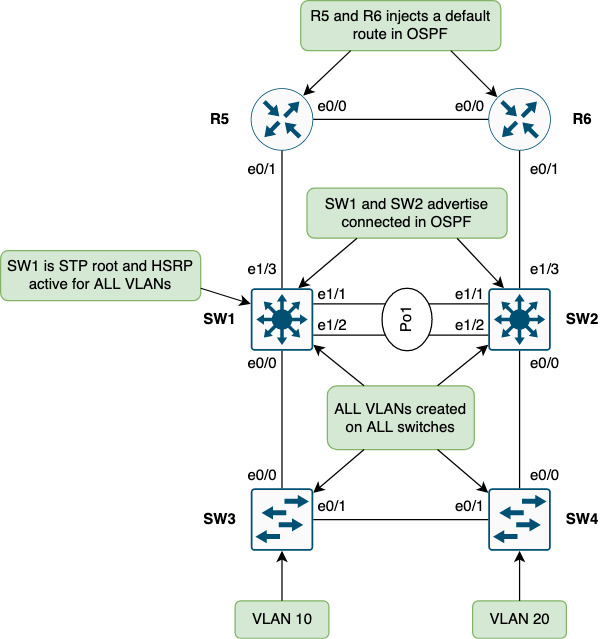
SW1 and SW2 function as the boundary between L2 and L3. They run HSRP with SW1 being the STP root and having the HSRP active state.
For routing, SW1 and SW2 participates in OSPF that is run between these nodes:
- SW1 <-> R5
- R5 <-> R6
- R6 <-> SW2
Note that currently no routing is configured between SW1 and SW2. The LAG (Po1) between these switches run L2-only.
All inter-switch links are trunks and all VLANs are allowed on them (no pruning of VLANs anywhere).
SW3 and SW4 are access switches. A per-switch VLAN has been created to try and keep VLANs localized per access switch. Not shown in the topology could be a VLAN that needs stretching due to legacy applications requiring broadcast or due to roaming of wifi. For now, focus is on the shown topology.
In essence the L2 domain is a square.
Why
Multiple reasons exist as to why a network might look like this:
- Cost
- Knowledge
- Streamlining
- Physical constraints
Each one of these reasons are detailed in below sections.
Cost
Building L2 networks like this is usually cheaper than creating a L3 network with L2 services on top. Both when it comes to selecting the platforms that offer these features but also the license required to use them. Service and support on higher-end platforms tend to be higher as well. All in all adding to the total cost of the install base.
Knowledge
A classical network might be designed due to lack of knowledge of what you can do technology-wise. The people who are to maintain it once implemented might not have the know-how and experience of working with a modern network.
Perhaps there hasn’t been allocated room in the budget to educate the staff. Or you simply cannot hire more knowledable people either due to cost or maybe there simply isn’t any skilled people to get.
Streamlining
This is what the company has on all its sites and it works for them. Keeping things streamlined has great value for being able to operate, document, and troubleshoot a network.
Physical Constraints
The building housing this network does not have enough fiber, hence the daisy chaining of the access switches. Also, perhaps the distribution switches do not have enough ports in the to have a link to every access node.
Issues
All designs have disadvantages. This type of network is no different. In below sections I’ll address the shortcomings in this design.
Issue #1 - Sub-optimal Paths
SW3 has a direct link to SW1 which is good. SW4, however, must traverse SW2 to reach SW1, the STP root and HSRP active switch. Mind that STP has logically blocked the link between SW3 and SW4. Such traffic aggregation for the SW1-SW2 link applies for all switches that might be indirectly connected to SW1 - like SW4 in this case.
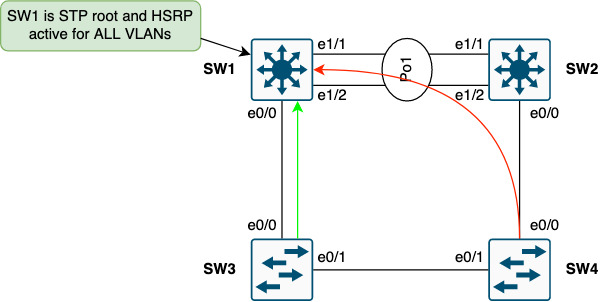
In case the uplink on SW3 fails, now traffic from SW3 to SW1 must traverse both SW4 and SW2.
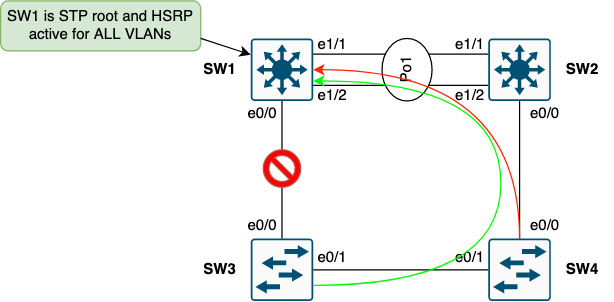
These inherent choke points in such a design might render the network sluggish and not performing as expected. It can be difficult to troubleshoot these performance incidents and prevent them without either re-designing the network or implement QoS which will add a great deal of complexity to the network and potentially not even be able to solve the performance issues.
You might be thinking that a solution could be to upgrade the bandwidth of the inter-switch links. Technically this could work, but typically you don’t have this option because of the lower-end platform used for the access layer has fixed uplink ports of lower speed. Or the cost of upgrading the uplink modules and SFPs is too high compared to the cost of installing more fibers.
Consider if ingress traffic is forwarded to SW2 instead of SW1. This will cause sub-optimal pathing between SW2 and SW3.
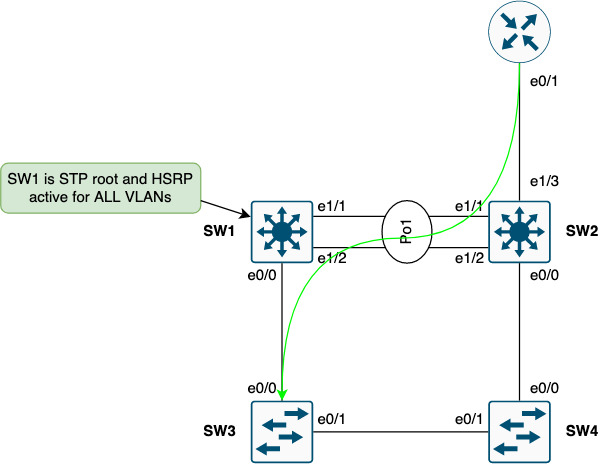
Issue #2 - Oversubscription
Having sub-optimal paths lead to the oversubscription shown below:
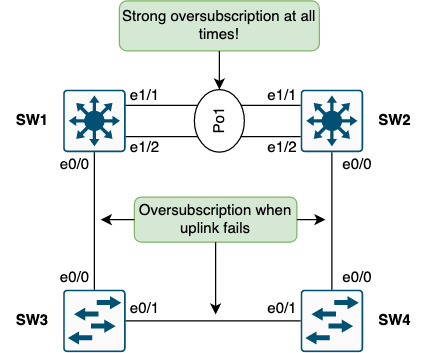
The SW1-SW2 link will always be subject to oversubscription when the gateway of endpoints is switched through SW2 instead of directly to SW1. Also, in case of an uplink failure, the entire traffic load for the specific switch must traverse other switches to get to SW1. This is far from optimal.
Issues #3 - Downstream Pack Flood
This issue requires a few facts and state outputs to understand what is going on and why this is an issue.
- Vlan10 has subnet 10.0.10.0/24
- All switches have an SVI in Vlan10
- SW3: 10.0.10.3
- SW4: 10.0.10.4
We can find the MAC address of SW3’s Vlan10 SVI by looking at the ARP table on SW1:
! SW1:
SW1#sh ip arp 10.0.10.3
Protocol Address Age (min) Hardware Addr Type Interface
Internet 10.0.10.3 57 aabb.cc80.2000 ARPA Vlan10
SW1#sh mac address-table address aabb.cc80.2000 vlan 10
Mac Address Table
-------------------------------------------
Vlan Mac Address Type Ports
---- ----------- -------- -----
10 aabb.cc80.2000 DYNAMIC Et0/0
Total Mac Addresses for this criterion: 1
SW1#
SW3’s SVI in VLan10 is reachable out Eth0/0 which is what we expect. Let’s have a look at SW2:
! SW2:
SW2#sh ip arp 10.0.10.3
Protocol Address Age (min) Hardware Addr Type Interface
Internet 10.0.10.3 52 aabb.cc80.2000 ARPA Vlan10
SW2#sh mac address-table address aabb.cc80.2000 vlan 10
Mac Address Table
-------------------------------------------
Vlan Mac Address Type Ports
---- ----------- -------- -----
SW2#
Notice the CAM table (MAC address table) on SW2 does not have an entry for SW3’s Vlan10 SVI MAC. This means that when traffic is forwarded to SW2 from R6 and is destined to anything in Vlan10 it will be flooded. The concept is called “downstream pack flood” and will cause unnecessary loads of traffic for all links downstream from SW2.
Why doesn’t SW2 have this entry? Because the default timer for ARP is 4 hours and the default timer for the CAM table is 5 minutes! So, we know about the L2 destination from the ARP cache, but since no traffic is received on any of SW2’s ports for the endpoints connected to Vlan10, the CAM entries will time out before the ARP entries do. And the control plane of L2 is data plane driven so the only means we have to get traffic to its destination is to flood it.
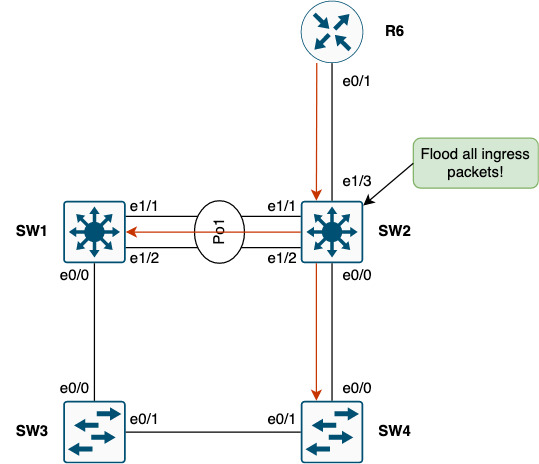
To prove this point a ping to SW3’s IP in Vlan10 (10.0.10.3) is performed on R6 which will send the packets to SW2:
! R6:
R6#sh ip route 10.0.10.3
Routing entry for 10.0.10.0/24
Known via "ospf 1", distance 110, metric 20, type extern 2, forward metric 10
Last update from 10.0.26.2 on Ethernet0/1, 22:38:13 ago
Routing Descriptor Blocks:
* 10.0.26.2, from 2.2.2.2, 22:38:13 ago, via Ethernet0/1
Route metric is 20, traffic share count is 1
R6#sh cdp nei e0/1 | be ^Device
Device ID Local Intrfce Holdtme Capability Platform Port ID
SW2 Eth 0/1 165 R S I Linux Uni Eth 1/3
Total cdp entries displayed : 1
R6#
If we then look at the packets as they arrive on SW4’s uplink e0/0, we see that the ICMP echo requests in fact was sent to SW4:

Besides from the two CDP packets noting the location of this capture, five ICMP echo request messages are received at SW4, meaning they were flooded by SW2! A very unwanted situation.
Issues #4 - Traffic Blackholing at HSRP Active Node
SW1, the active HSRP node, only has one path upstream. If this fails traffic will be blackholed. Currently SW1 has a default OSPF route received from R5:
! SW1:
SW1#sh ip route 8.8.8.8
% Network not in table
SW1#sh ip route 0.0.0.0
Routing entry for 0.0.0.0/0, supernet
Known via "ospf 1", distance 110, metric 1, candidate default path
Tag 1, type extern 2, forward metric 10
Last update from 10.0.15.5 on Ethernet1/3, 00:01:16 ago
Routing Descriptor Blocks:
* 10.0.15.5, from 5.5.5.5, 00:01:16 ago, via Ethernet1/3
Route metric is 1, traffic share count is 1
Route tag 1
SW1#sh ip cef 8.8.8.8
0.0.0.0/0
nexthop 10.0.15.5 Ethernet1/3
SW1#
If the uplink fails as shown below, this path will disapear and SW1 will have nowhere to send traffic.
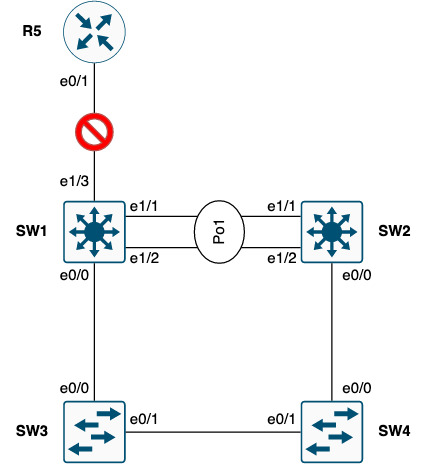
Here a link failure is simulated and no route exist yet SW1 remains HSRP active.
! SW1:
*Oct 8 19:58:33.266: %OSPF-5-ADJCHG: Process 1, Nbr 5.5.5.5 on Ethernet1/3 from FULL to DOWN, Neighbor Down: Interface down or detached
SW1#
*Oct 8 19:58:35.259: %LINK-5-CHANGED: Interface Ethernet1/3, changed state to administratively down
*Oct 8 19:58:36.259: %LINEPROTO-5-UPDOWN: Line protocol on Interface Ethernet1/3, changed state to down
SW1#sh ip route 0.0.0.0 0.0.0.0
% Network not in table
SW1#sh ip cef 8.8.8.8
0.0.0.0/0
no route
SW1#sh standby vlan 10 brief
P indicates configured to preempt.
|
Interface Grp Pri P State Active Standby Virtual IP
Vl10 10 101 Active local 10.0.10.254 10.0.10.1
SW1#
As HSRP is still active on SW1, traffic will be drawn here and dropped.
Optimizations and Solutions
This section looks at how you can address some of the shortcomings listed above. Not every issue can be fixed with this topology, though.
Path Optimization
The sub-optimal paths shown above can all be optimized with these changes:
- Make SW1 STP root and HSRP active for half the VLANs
- Make SW2 STP root and HSRP active for the remaining VLANs
- Ensure ingress routing to the HSRP active node
- SW1 and SW2 will advertise only the VLANs for which they’re HSRP active plus a site aggregate
NOTE! The aggregation might not be feasible. The IP plan must allow for it. In this example VLANs 10 (10.0.10.0/24) and 20 (10.0.20.0/24) have been aggregated to 10.0.0.0/19. If you use subnets within this aggreate elsewhere in the network it is very likely that communication issues arrise in the event of a link or node failure! You should never use component subnets of an aggreate in other routing domains.
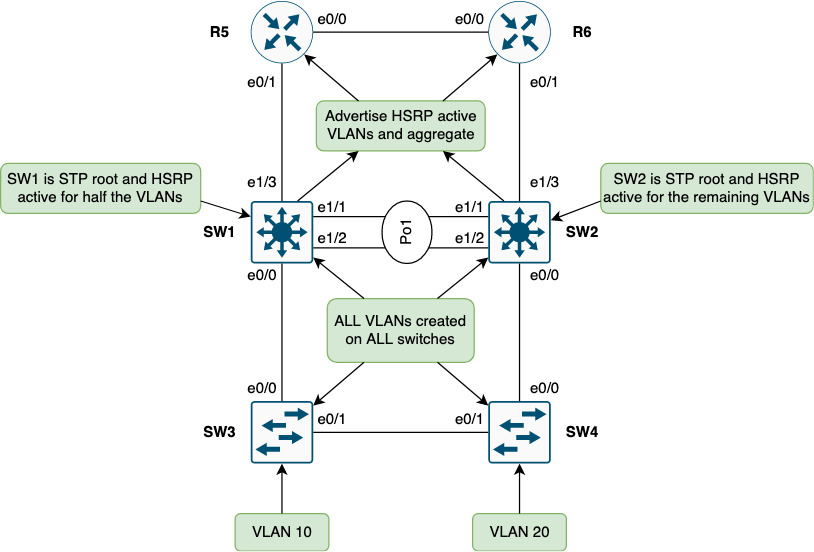
STP and HSRP alignment:
! SW1:
SW1#sh span root
Root Hello Max Fwd
Vlan Root ID Cost Time Age Dly Root Port
---------------- -------------------- --------- ----- --- --- ------------
VLAN0001 24577 aabb.cc00.1000 0 2 20 15
VLAN0010 24586 aabb.cc00.1000 0 2 20 15
VLAN0020 24596 aabb.cc00.3000 56 2 20 15 Po1
SW1#
SW1#sh standby brie
P indicates configured to preempt.
|
Interface Grp Pri P State Active Standby Virtual IP
Vl10 10 101 P Active local 10.0.10.254 10.0.10.1
Vl20 20 100 P Standby 10.0.20.254 local 10.0.20.1
SW1#
Here SW1 is STP root and HSRP active for VLAN10. SW2 is STP root and HSRP active for VLAN20.
And the state of routing on R5 after the traffic engineering changes:
! R5:
R5#sh ip osp data | be External
Type-5 AS External Link States
Link ID ADV Router Age Seq# Checksum Tag
0.0.0.0 5.5.5.5 1141 0x8000002D 0x004C26 1
0.0.0.0 6.6.6.6 1667 0x8000002B 0x00323E 1
1.1.1.1 1.1.1.1 191 0x80000001 0x009BFC 0
2.2.2.2 2.2.2.2 268 0x8000002C 0x00F86C 0
5.5.5.5 5.5.5.5 1145 0x8000002D 0x00123A 0
6.6.6.6 6.6.6.6 1667 0x8000002C 0x00C77D 0
10.0.0.0 1.1.1.1 243 0x80000002 0x00A907 0
10.0.0.0 2.2.2.2 125 0x80000001 0x008D20 0
10.0.10.0 1.1.1.1 191 0x80000001 0x00D8AF 0
10.0.20.0 2.2.2.2 268 0x8000002C 0x00F559 0
R5#
R5#sh ip route ospf | be ^Gateway
Gateway of last resort is not set
1.0.0.0/32 is subnetted, 1 subnets
O E2 1.1.1.1 [110/20] via 10.0.15.1, 00:02:57, Ethernet0/1
2.0.0.0/32 is subnetted, 1 subnets
O E2 2.2.2.2 [110/20] via 10.0.56.6, 00:18:42, Ethernet0/0
6.0.0.0/32 is subnetted, 1 subnets
O E2 6.6.6.6 [110/20] via 10.0.56.6, 00:18:42, Ethernet0/0
10.0.0.0/8 is variably subnetted, 8 subnets, 3 masks
O E2 10.0.0.0/19 [110/20] via 10.0.15.1, 00:03:49, Ethernet0/1
O E2 10.0.10.0/24 [110/20] via 10.0.15.1, 00:02:57, Ethernet0/1
O E2 10.0.20.0/24 [110/20] via 10.0.56.6, 00:02:37, Ethernet0/0
O 10.0.26.0/24 [110/20] via 10.0.56.6, 00:18:42, Ethernet0/0
R5#
The OSPF database reflects that SW1 (1.1.1.1) and SW2 (2.2.2.2) both advertise the aggregate 10.0.0.0. Only SW1 advertises 10.0.10.0 and only SW2 advertises 10.0.20.0. R5’s routing table also shows this.
Let’s check how R6 routes traffic to Vlan10:
! R6:
R6#sh ip route 10.0.10.3
Routing entry for 10.0.10.0/24
Known via "ospf 1", distance 110, metric 20, type extern 2, forward metric 20
Last update from 10.0.56.5 on Ethernet0/0, 00:06:18 ago
Routing Descriptor Blocks:
* 10.0.56.5, from 1.1.1.1, 00:06:18 ago, via Ethernet0/0
Route metric is 20, traffic share count is 1
R6#sh cdp nei e0/0 | be ^Device
Device ID Local Intrfce Holdtme Capability Platform Port ID
R5 Eth 0/0 130 R B Linux Uni Eth 0/0
Total cdp entries displayed : 1
R6#
Traffic is forwarded to the HSRP active node. The path it takes is R6 -> R5 -> SW1 -> SW3 which is optimal as shown here:
! R6:
R6#traceroute 10.0.10.3 numeric ttl 1 10 timeout 1 so lo0
Type escape sequence to abort.
Tracing the route to 10.0.10.3
VRF info: (vrf in name/id, vrf out name/id)
1 10.0.56.5 0 msec 0 msec 1 msec
2 10.0.15.1 1 msec 1 msec 0 msec
3 10.0.10.3 1 msec * 1 msec
R6#
All egress traffic now also takes a direct path to the adjacent upstream HSRP node.
Network Convergence Upon Uplink Failure
When the HSRP active node loses its uplink it must have an alternate path for routing traffic upstream. There are a couple of ways we can address the traffic blackholing issue:
- Create a L3 link between SW1 and SW2 and enable OSPF on it
- NOTE! Must be a stub area if you redistributed connected into OSPF! Otherwise ingress routing does not follow the HSRP active node
- Alternatively run another protocol like BGP
- Even a floating static default route would suffice
- Track the uplink and decrement the priority to let the peer node become HSRP active
The tracking solution relies on a tracking object being notified when the link fails. Unfortunately a link can fail in many ways. Having a protocol send keepalives (hellos) out a link will ensure the link is usable, hence it is a more reliable method. Be mindful when establishing routing via this link. It can be a bit tricky to get working the intended way. Especially if symmetric routing is required.
The downside of configuring OSPF between SW1 and SW2 is that the HSRP active role stays on SW1 - even when its uplink fails. This puts more stress on the link as egress traffic now takes a u-turn on SW1.
A traceroute from SW3 when the uplink on SW1 is down:
! SW3:
SW3#traceroute 10.0.26.6
Type escape sequence to abort.
Tracing the route to 10.0.26.6
VRF info: (vrf in name/id, vrf out name/id)
1 10.0.10.253 1 msec 1 msec 0 msec
2 10.0.12.2 1 msec 1 msec 1 msec
3 10.0.26.6 2 msec
SW3#
Here the first hop is still SW1 (10.0.10.253) where traffic is u-turned and forwarded to SW2, the second hop.
Ingress routing is direct as the prefix of Vlan10 is no longer advertised and we fall back to the aggregate route. This is the view from R6:
! R6:
R6#sh ip route 10.0.10.3
Routing entry for 10.0.0.0/19
Known via "ospf 1", distance 110, metric 20, type extern 2, forward metric 10
Last update from 10.0.26.2 on Ethernet0/1, 01:13:40 ago
Routing Descriptor Blocks:
* 10.0.26.2, from 2.2.2.2, 01:13:40 ago, via Ethernet0/1
Route metric is 20, traffic share count is 1
R6#traceroute 10.0.10.3 numeric ttl 1 10 timeout 1 source lo0
Type escape sequence to abort.
Tracing the route to 10.0.10.3
VRF info: (vrf in name/id, vrf out name/id)
1 10.0.26.2 0 msec 0 msec 1 msec
2 10.0.10.3 1 msec * 2 msec
R6#
Downstream Pack Flood
The flooding has been prevented due to the ingress traffic engineering, but it is still an issue in case of an uplink failure on either SW1 or SW2. To alleviate this we change the ARP timeout for the VLANs SW1 and SW2 are HSRP standby, meaning VLAN20 and VLAN10, respectively.
! SW1:
interface Vlan20
arp timeout 300
SW1#sh int vlan 20 | in ARP Timeout|Vlan
Vlan20 is up, line protocol is up
ARP type: ARPA, ARP Timeout 00:05:00
SW1#
! SW2:
interface Vlan10
arp timeout 300
SW2#sh int vlan 10 | in ARP Timeout|Vlan
Vlan10 is up, line protocol is up
ARP type: ARPA, ARP Timeout 00:05:00
SW2#
This will make the switches perform an ARP looking instead of flooding the traffic upon ingress.
Open Issues
The above optimizations do not account for the case where SW3 loses its uplink to SW1. In that event, communication still goes through both SW4 and SW2.
The oversubscription issue is also still present and is inherent to this design.
The downstream pack flood issue has been solved, though. This is because we ensured to get ingress traffic to be forwarded to the HSRP active node. We even ensured that in case of a link failure that traffic isn’t flooded to the the ARP timer adjustment.
Conclusion
In this post we found out that building L2 domains using square topologies come with significant trade-offs:
- Sub-optimal paths
- Oversubscription
- Downstream pack flood
- Blackholing of traffic
Yet there are valid reasons and restrictions you might be forced into such a design:
- Cost
- Knowledge
- Streamligning
- Physical constraints
Fixes and optimizations implemented for this design:
- Load distribution of STP root and HSRP active role between SW1 and SW2
- Ingress traffic engineering using shortest prefix length routing
- Establish routing between SW1 and SW2
- Change ARP timer for HSRP standby VLANs on SW1 and SW2
Besides from the oversubscription issues that are inherent to this type of design, it is possible to address the shortcomings with proper implementation of the protocols in play.
Mind that you’l need to ensure that the bandwidth of the links in the design are capable of carrying the needed traffic. With the above traffic engineering implementation, traffic is always forwarded to the HSRP active node, regardless of the speed of the links. We utilized the shortest prefix length which takes precedence over routing metrics like cost and administrative distance. This bandwidth consideration is also true in case of an uplink failure on an access switch (SW3 or SW4).
This design has many moving parts that can be quite the challenge to get working as desired.
I hope you enjoyed this design post. Thanks for reading.