Services
DHCP
DHCP provides a dynamic way of handing out an IP configuration to clients. Â I’ll use the following topology.

SW1 is purely a L2 switch with no routing capabilities for this topology.
Let’s start by configuring a DHCP pool on R2.
! R2 interface configuration: R2(config)#int e0/0 R2(config-if)#ip address 10.0.12.254 255.255.255.0 R2(config-if)#no shut ! R2 DHCP Pool configuration: R2(config)#ip dhcp excluded-address 10.0.12.254 R2(config)# R2(config)#ip dhcp pool R1 R2(dhcp-config)#network 10.0.12.0 /24 R2(dhcp-config)#default-router 10.0.12.254 R2(dhcp-config)#dns-server 8.8.8.8 8.8.4.4 R2(dhcp-config)#domain-name cisco.com
By default the DHCP server service is running. It can be disabled via the no service dhcp command.
And we can verify the DHCP pool on R2:
! R2 DHCP Pool verification: R2#sh ip dhcp pool Pool R1 : Utilization mark (high/low). : 100 / 0 Subnet size (first/next) : 0 / 0 Total addresses : 254 Leased addresses : 0 Pending event : none 1 subnet is currently in the pool : Current index IP address range Leased addresses 10.0.12.1 10.0.12.1 - 10.0.12.254 0 R2#
And the configuration of R1 as a DHCP client:
! R1 DHCP client configuration: R1(config-if)#int e0/0 R1(config-if)#ip address dhcp R1(config-if)#no shut
Cisco IOS allocates addresses from the range in an ascending order starting at the first available address (.1 in this case). Â Note I excluded R2s .254 address from the range before defining the DHCP pool on R2.
Shortly we should see that R1 receives an IP configuration:
! R1 log and verification: *Nov 9 19:32:28.316: %DHCP-6-ADDRESS_ASSIGN: Interface Ethernet0/0 assigned DHCP address 10.0.12.1, mask 255.255.255.0, hostname R1 R1# R1#sh ip int brief Interface IP-Address OK? Method Status Protocol Ethernet0/0 10.0.12.1 YES DHCP up up
On R2 we can now see a binding for the pool:
! R2 DHCP bindings:
R2#sh ip dhcp binding
Bindings from all pools not associated with VRF:
IP address Client-ID/ Lease expiration Type
Hardware address/
User name
10.0.12.1 0063.6973.636f.2d61. Nov 10 2017 09:32 PM Automatic
6162.622e.6363.3030.
2e35.3030.302d.4574.
302f.30
R2#
Packets
The process of obtaining an IP configuration from a DHCP server uses four messages:
[table id=8 /]
DHCP uses these ports:
- UDP/68
- Client port (bootpc)
- UDP/67
- Server port (bootps)
Let’s have a look at the capture of the process:

This is the DHCP Discover packet. It is a broadcast and the client has set the broadcast flag, meaning that the client wants to receive a reply via broadcast. In IOS you can control the broadcast flag under an interface using the ip dhcp client broadcast-flag [set|clear]. Per-RFC the client source IP address must always be set to 0.0.0.0 prior to obtaining an IP address.
Let’s have a look at the Offer the server sends.
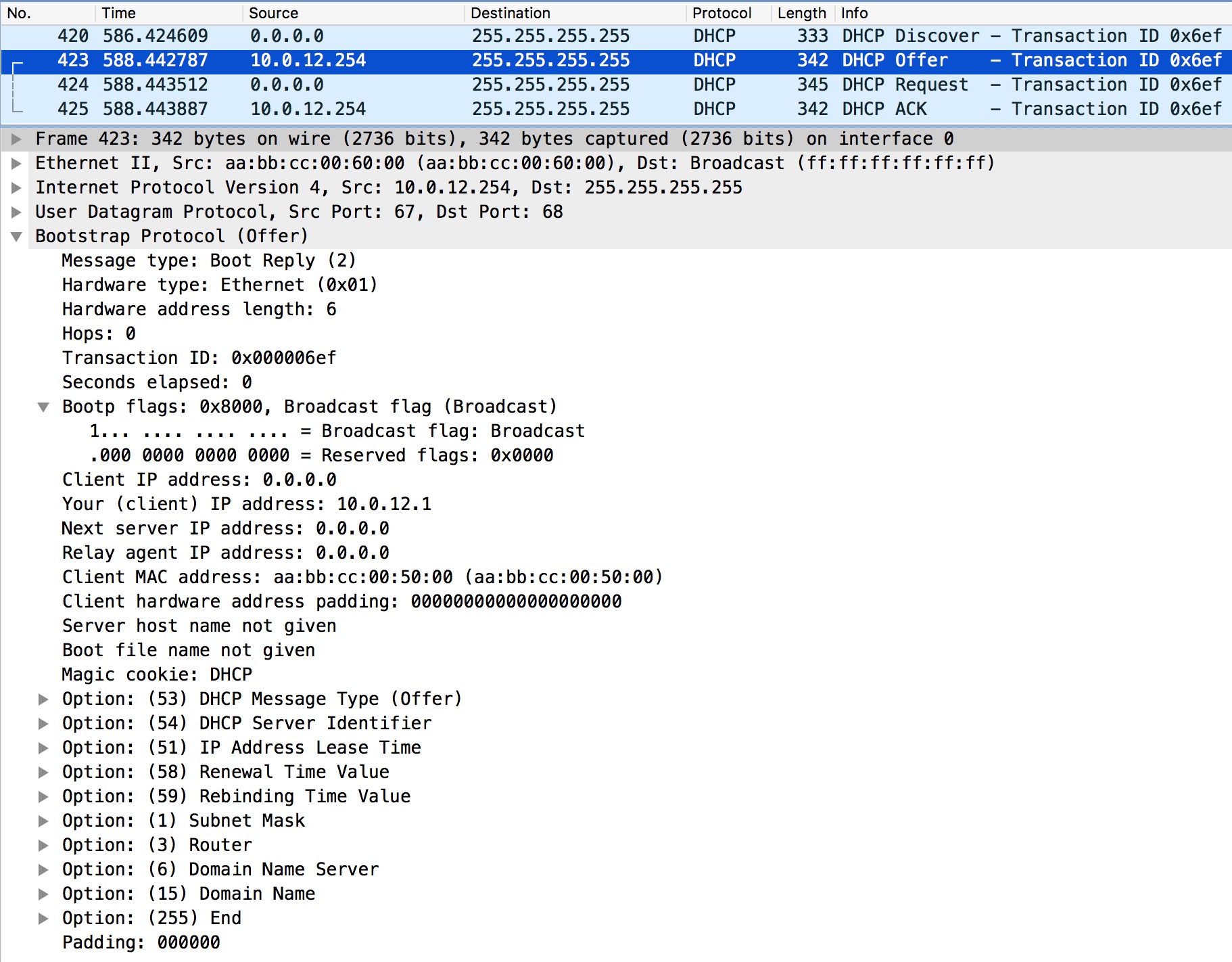
We see the “Your (client) IP address” and a bunch of options like Subnet Mask and Router. If the client wishes to use the offer, it must send a DHCP Request message:
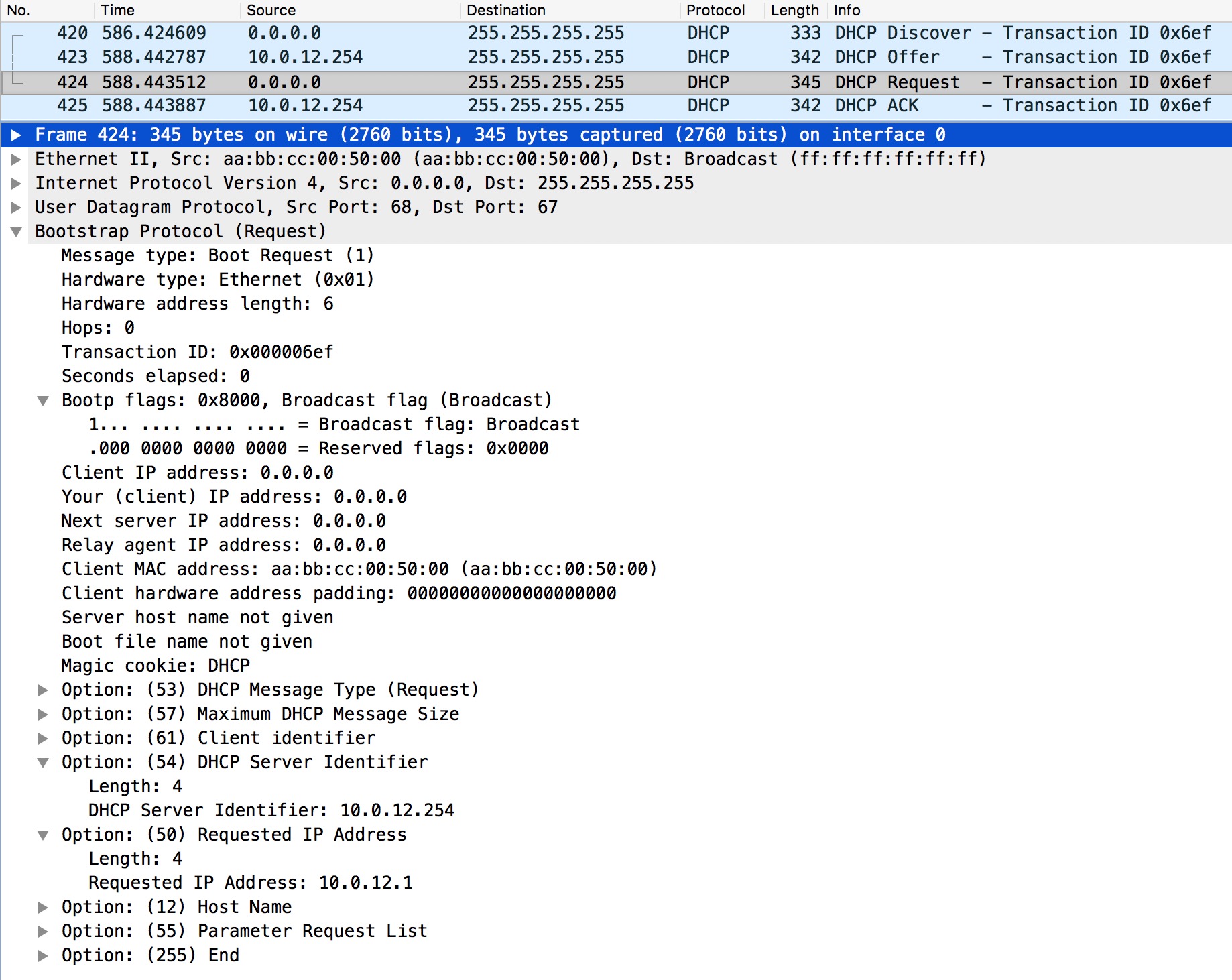
The client requests the IP address using Option 50. It also lists the DHCP Server Identifier, because multiple DHCP servers could be present on the subnet.
Finally the server Acknowledges the request from the client, letting it know that it has created a binding for the client.

This wraps up the DHCP messages sent between the client and server. Later I’ll cover the DHCP Relay function.
Reservations
You might want to lock down a binding to a specific client. I could be a printer og some other device you do not want have the IP address change. This is done using the client-id in a DHCP host pool.
If we look at the content of the Option 61 in the DHCP Discover message, we see the client-id:
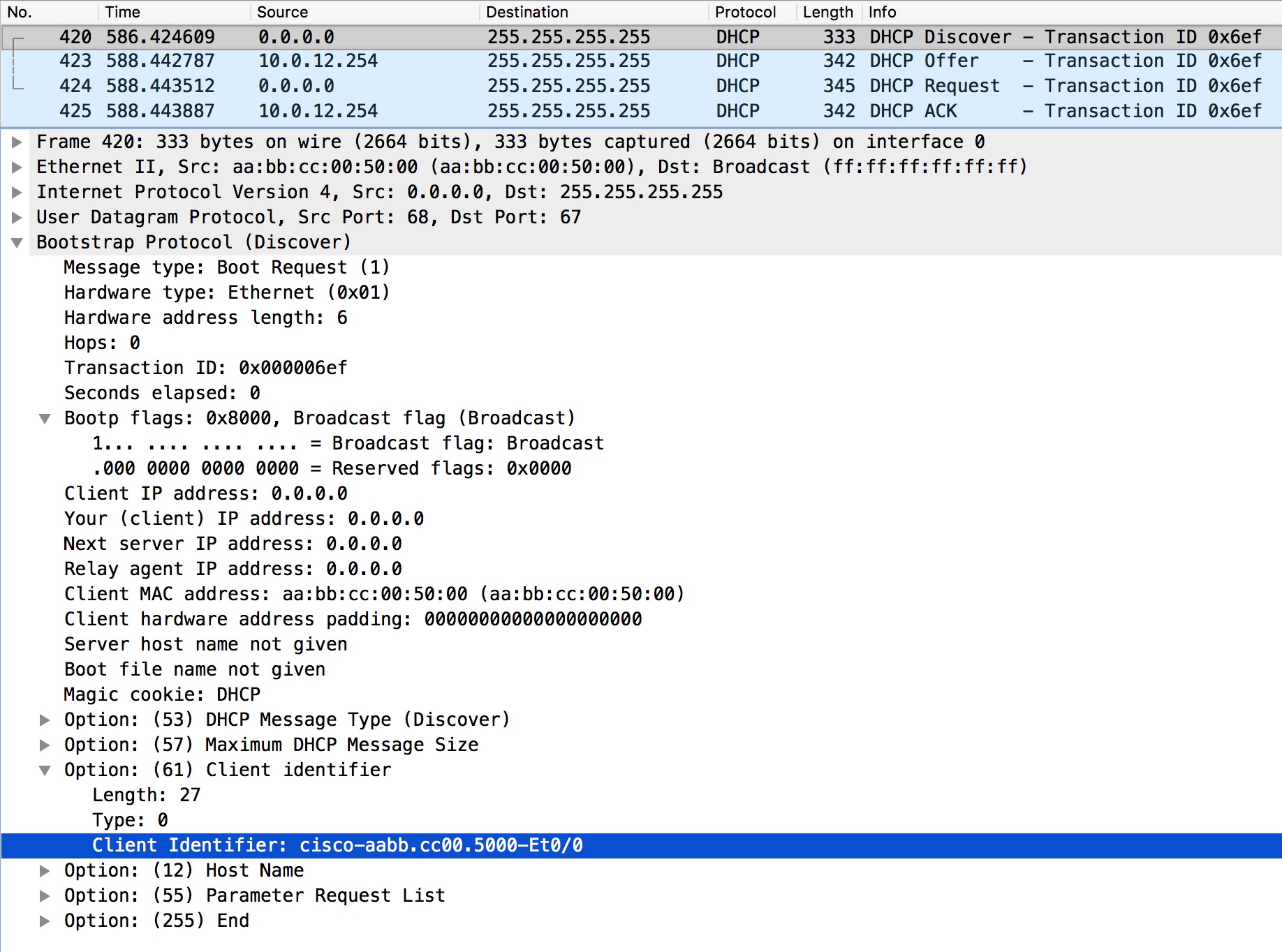
The Client Identifier option is not the hardware address of R1, but merely a string Cisco has chosen to implement as a client-id. As said, you can use this client-id to make a reservation (host pool) on R2. You can, however, also change the default client-id. To view the lease on R1:
! R1 DHCP lease verification:
R1#sh dhcp lease
Temp IP addr: 10.0.12.1 for peer on Interface: Ethernet0/0
Temp sub net mask: 255.255.255.0
DHCP Lease server: 10.0.12.254, state: 5 Bound
DHCP transaction id: 9C3
Lease: 86400 secs, Renewal: 43200 secs, Rebind: 75600 secs
Temp default-gateway addr: 10.0.12.254
Next timer fires after: 11:59:48
Retry count: 0 Client-ID: cisco-aabb.cc00.5000-Et0/0
Client-ID hex dump: 636973636F2D616162622E636330302E
353030302D4574302F30
Hostname: R1
R1#
Here we also see our client-id – both as a string, and in a hex dump as we saw in the capture.
To create a reservation for R1, we have to create a host pool on R2. A host pool is based on a host address and a client-identifier to locate the pool and hence the address specified in the pool.
! R1 Manual client-id: R1(config)#int e0/0 R1(config-if)#ip address dhcp client-id e0/0
! R2 DHCP host pool: R2(config)#ip dhcp pool R1host R2(dhcp-config)#host 10.0.12.1 255.255.255.0 R2(dhcp-config)#client-id 01aa.bbcc.0050.00 R2(dhcp-config)#default-router 10.0.12.254 R2(dhcp-config)#dns-server 8.8.8.8 R2(dhcp-config)#domain-name cisco.com
To verify the host pool on R2:
! R2 DHCP host pool verification:
R2#sh ip dhcp binding
Bindings from all pools not associated with VRF:
IP address Client-ID/ Lease expiration Type
Hardware address/
User name
10.0.12.1 01aa.bbcc.0050.00 Infinite Manual
R2#
We see that the lease is infinite and of type manual. So we have our reservation configured. Now what about the client-id this time? I configured a weird looking string for the client-id. Because we set the client-id on R1 to that of its Eth0/0 interface, R1 will use the MAC address of its interface in the client-id, but it will prepend the media type to the MAC address (01 for Ethernet) resulting in the 01aa.bbcc.0050.00 string. We could also have defined the client-id as an ASCII string, like R1. Let’s have a look at this:
! R1 DHCP client-id ASCII: R1(config)#int e0/0 R1(config-if)#ip dhcp client client-id ascii R1 R1(config-if)#ip address dhcp
When specifying the client-id as an ascii value, the router will prepend 00 to the string you define. The means that for R1 the client-id hex value is:
! R1 debug dhcp detail: R1#debub dhcp detail DHCP client activity debugging is on (detailed) R1# *Nov 9 20:54:06.772: DHCP: SDiscover attempt # 3 for entry: *Nov 9 20:54:06.772: Temp IP addr: 0.0.0.0 for peer on Interface: Ethernet0/0 *Nov 9 20:54:06.772: Temp sub net mask: 0.0.0.0 *Nov 9 20:54:06.772: DHCP Lease server: 0.0.0.0, state: 3 Selecting *Nov 9 20:54:06.772: DHCP transaction id: 7B9 *Nov 9 20:54:06.772: Lease: 0 secs, Renewal: 0 secs, Rebind: 0 secs *Nov 9 20:54:06.772: Next timer fires after: 00:00:04 *Nov 9 20:54:06.772: Retry count: 3 Client-ID: R1 *Nov 9 20:54:06.772: Client-ID hex dump: 5231 *Nov 9 20:54:06.772: Hostname: R1
Notice the Client-ID hex dump: 5231
This has to be prepended with 00, resulting in 0052.31 as the client-id we’d use in the DHCP host pool on R2. This we can also see if we debug on R2:
! R2 debug ip dhcp server packet detail: R2#debug ip dhcp server packet detail DHCP server packet detail debugging is on. R2# *Nov 9 20:59:56.927: DHCPD: DHCPDISCOVER received from client 0052.31 on interface Ethernet0/0.
Relay
Usually the DHCP server resides in some Data Center and not on the same subnet as the clients. This provides a challenge as the DHCP messages are broadcast. You can configure a router to relay the DHCP messages to the DHCP server via unicast.
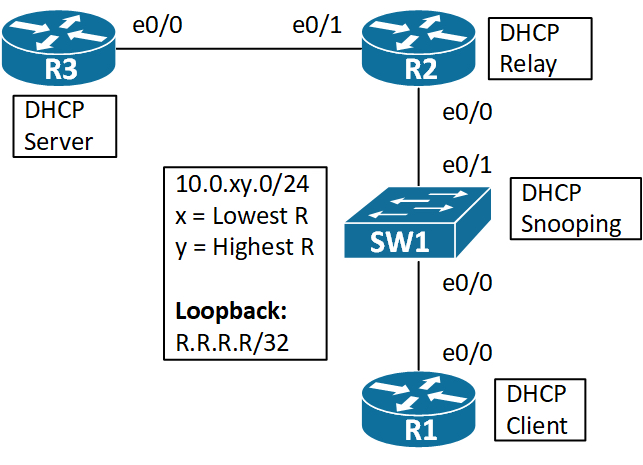
If we extend the topology a bit and make R2 a regular router and add R3 as the DHCP server, we can have a look at the relay function and what it does to the messages.
! R2 DHCP Relay configuration: R2(config)#int e0/0 R2(config-if)#ip helper-address 3.3.3.3 R2(config-if)#
I’ve also moved the  a DHCP pool from R2 to R3.
Let’s see a capture taken on R3:
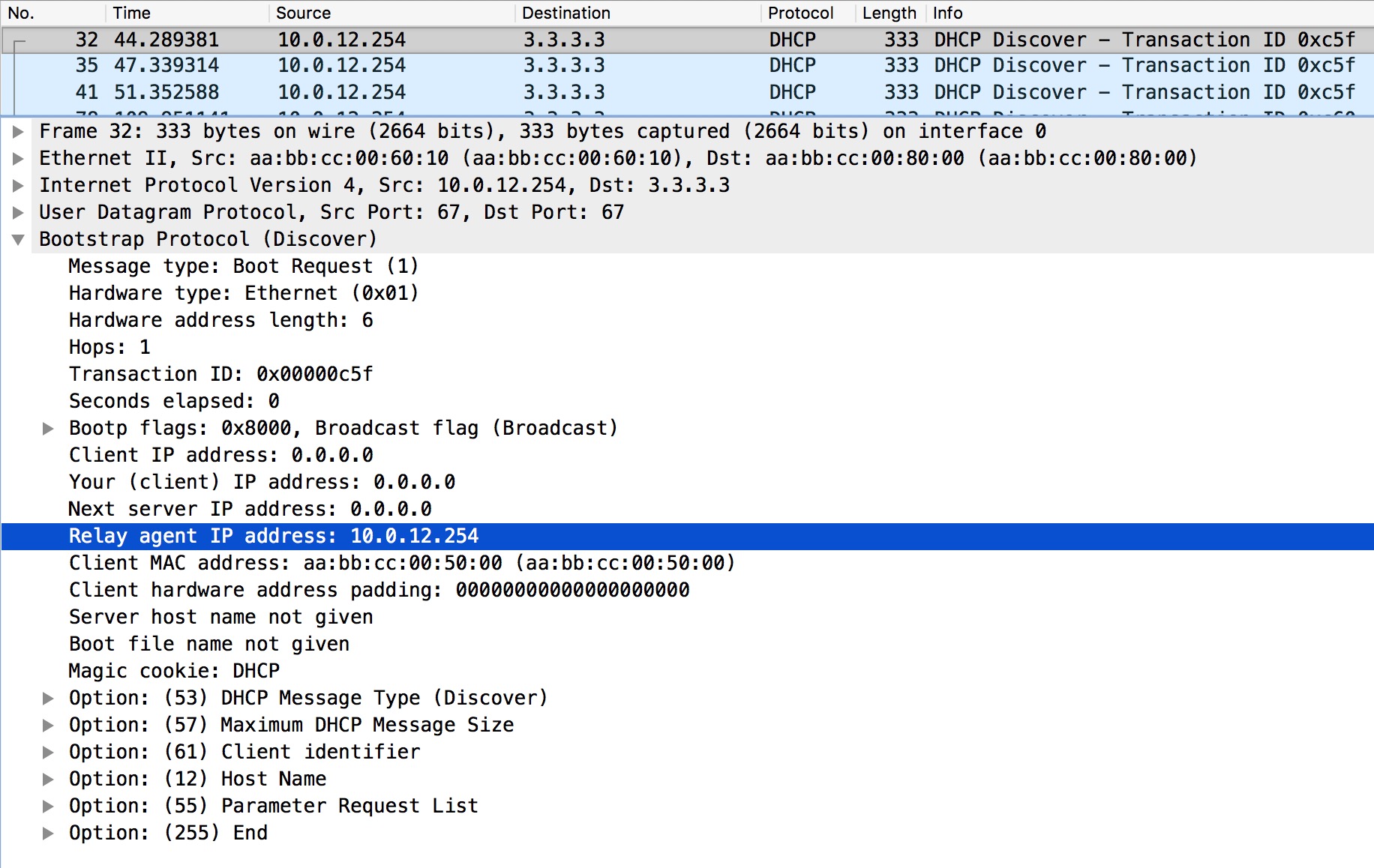
Notice the L3 header of this packet. It has the source IP of R2s Eth0/0 interface facing R1. Also R2 has set the giaddr (Relay agent IP address). This address is used on the DHCP server to find the correct DHCP pool and to tell the DHCP server where to send the DHCP Offer. Especially the last part about the destination address of the Offer is important as it requires that R3 has a route back to 10.0.12.254 in this case. If it does not have route back, the client will never receive the Offer.
As soon as we have routing in place R1 will receive the Offer from R3 via R2.
Snooping
It is fairly easy to set up a DHCP server. It is therefore also a concern that someone might accidentally or intentionally plug in a DHCP server in an access port. This can cause reachability issues, as the rouge DHCP server perhaps lease address not in a routable range. Or even worse it is a malicious attack and the attacker hands out routable addresses, but with the attackers IP as the gateway for clients making a MITM (Man In The Middle) attack possible. For these reasons we have DHCP Snooping
DHCP Snooping works by assigning roles to switchports. By default all ports are treated as untrusted, meaning we cannot have a DHCP server attached to them. This means that the port we do have a DHCP server located on (usually the uplink ports) must be configured as trusted port. Let’s try to configure SW1 with DHCP Snooping.
! SW1 DHCP Snooping configuration: SW1(config)#ip dhcp snooping vlan 1 SW1(config)#ip dhcp snooping SW1(config)#int e0/1 SW1(config-if)#ip dhcp snooping trust SW1(config-if)#
First we define the VLANs for which we want to enable DHCP Snooping. Next we enable the feature. Lastly we configure the uplink port (connecting to R2) to be trusted.
If we look at a debug ip dhcp server packet detail on R2:
! R2 debug ip dhcp server packet detail: R2#debug ip dhcp server packet detail DHCP server packet detail debugging is on. R2# *Nov 10 22:29:59.057: DHCPD: inconsistent relay information. *Nov 10 22:29:59.057: DHCPD: relay information option exists, but giaddr is zero. R2#
Se see that it complains about inconsistent relay information. And the relay information option exists, but giaddr is zero. What does this all mean? When a switch is configured for DHCP Snooping, by default, it enables insertion of Option 82.
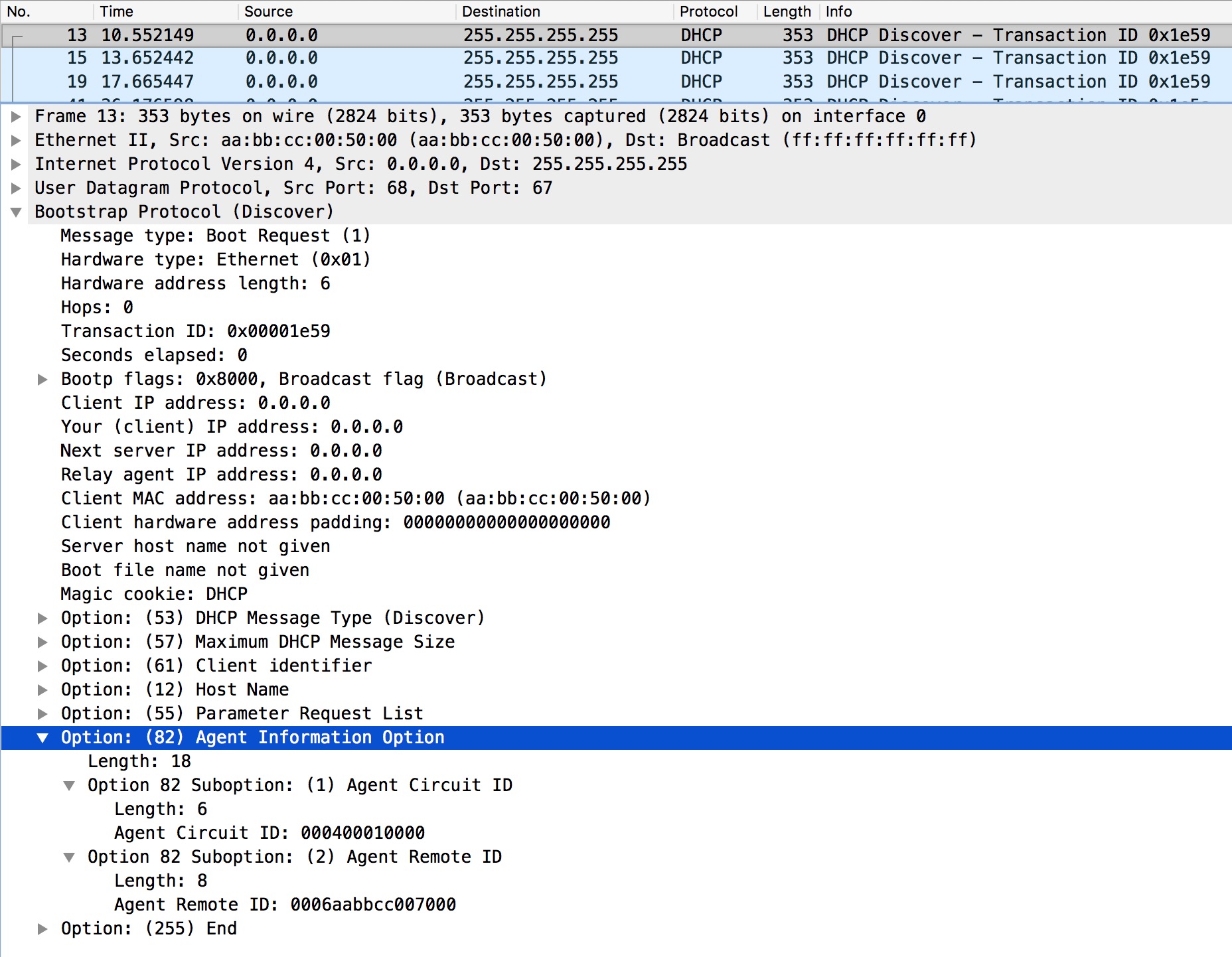
The Option 82 is used to provide additional information about a clients attachment to the network. This information can be leveraged by DHCP server to make a more granular selection of which IP to lease to the client within a pool. Given that the switch is not a router, it cannot insert a giaddr. Â I’d like to quote a section of RFC3046 regarding Option 82:
"Relay agents receiving a DHCP packet from an untrusted circuit with giaddr set to zero (indicating that they are the first-hop router) but with a Relay Agent Information option already present in the packet SHALL discard the packet and increment an error count."
In our situation the “first-hop-router” is SW1 and the relay agent is R2. When R2 receives a DHCP Discovery message from R1 containing the Option 82 inserted by SW1, it will discard the packet as we saw in the above debug. What are the solutions to this issue? We actually have a couple of solutions:
- Disable Option 82 insertion on SW1
- Trust the DHCP relay information on R2
- Interface basis
- Globally
! SW1 disable option 82: SW1(config)#no ip dhcp snooping information option SW1(config)#
Verify DHCP Snooping:
! SW1 DHCP Snooping verification: SW1#sh ip dhcp snooping Switch DHCP snooping is enabled Switch DHCP gleaning is disabled DHCP snooping is configured on following VLANs: 1 DHCP snooping is operational on following VLANs: 1 DHCP snooping is configured on the following L3 Interfaces: Insertion of option 82 is disabled circuit-id default format: vlan-mod-port remote-id: aabb.cc00.7000 (MAC) Option 82 on untrusted port is not allowed Verification of hwaddr field is enabled Verification of giaddr field is enabled DHCP snooping trust/rate is configured on the following Interfaces: Interface Trusted Allow option Rate limit (pps) ----------------------- ------- ------------ ---------------- Ethernet0/1 yes yes unlimited Custom circuit-ids: SW1#
On the relay server, R2, we can either trust option 82 globally or at the interface level:
! R2 trust option 82: R2(config)#ip dhcp relay information trust-all R2(config)# R2(config)# R2(config)#int e0/0 R2(config-if)#ip dhcp relay information trust R2(config-if)#
The debug on R2 with option 82 trusted:
! R2 debug ip dhcp server packet detail: R2#debug ip dhcp server packet detail DHCP server packet detail debugging is on. R2# *Nov 10 22:56:20.054: DHCPD: message is from trusted interface Ethernet0/0 *Nov 10 22:56:20.054: DHCPD: client's VPN is . *Nov 10 22:56:20.054: DHCPD: No option 125 *Nov 10 22:56:20.054: DHCPD: setting giaddr to 10.0.12.254.
Now the DHCP message is from trusted interface and R2 sets the giaddr to the receiving interface IP.
Snooping In The Data Center
Usually DHCP snooping is a feature enabled on our access switches in the campus network to protect against rogue DHCP servers. An unusual place to enable this feature is in the Data Center where the DHCP server is located. The reason for this is that we typically have full control over all devices in our Data Center and every device has a static IP configuration. But if we rely on DHCP in the DC too, we can leverage DHCP snooping.
I would like to use the following topology to demonstrate what happens when you enable DHCP snooping in the DC:[
]1
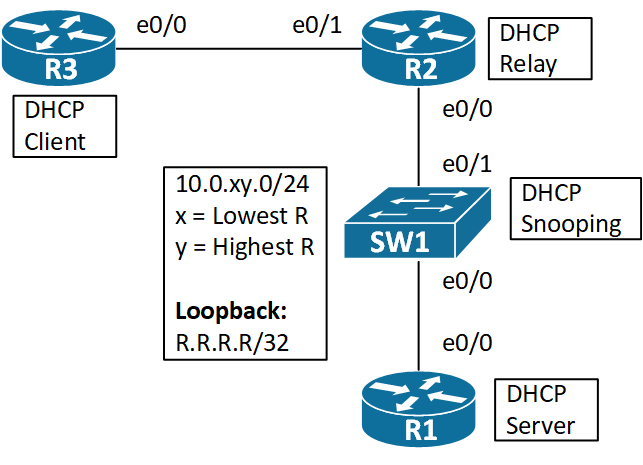
Now the DHCP server is located on R1 which is connected to the SW1 in our DC. R2 is the relay and R3 is the DHCP client.
First we instantly see that we need to configure the port on SW1 facing R1 as a trusted port.
! SW1 DHCP Snooping configuration: SW1(config)#int e0/0 SW1(config-if)#ip dhcp snooping trust SW1(config-if)#exit SW1(config)#ip dhcp snooping vlan 12 SW1(config)#ip dhcp snooping SW1(config)#
Now that DHCP snooping is enabled and we trust the port facing our DHCP server, we should be able to lease an address to our client, R3. This is not the case, though. Let’s see why:
! SW1 console log: SW1# *Dec 5 09:03:12.410: %DHCP_SNOOPING-5-DHCP_SNOOPING_NONZERO_GIADDR: DHCP_SNOOPING drop message with non-zero giaddr or option82 value on untrusted port, message type: DHCPDISCOVER, MAC sa: aabb.cc00.6000 SW1#
SW1 says that a non-zero giaddr or option82 value DHCP Discover was received on an untrusted port. This message was dropped. If we look inside the DHCP Discover that SW1 receives:

Here it is obvious that the giaddr is in fact non-zero. Since no Option 82 is present this is the cause why SW1 drops the packet. The only solution to this is to trust the port facing R2 (the relay agent):
! SW1 trust port to relay agent: SW1(config)#int e0/1 SW1(config-if)#ip dhcp snooping trust SW1(config-if)#
If we look at the debug ip dhcp snooping packet and event on SW1, we can see that the lease is successful:
! Debug ip dhcp snooping packet and event SW1: *Dec 5 09:22:17.786: DHCP_SNOOPING: message type : DHCPDISCOVER DHCP ciaddr: 0.0.0.0, DHCP yiaddr: 0.0.0.0, DHCP siaddr: 0.0.0.0, DHCP giaddr: 10.0.23.2, DHCP chaddr: aabb.cc00.8000 *Dec 5 09:22:19.801: DHCP_SNOOPING: message type : DHCPOFFER DHCP ciaddr: 0.0.0.0, DHCP yiaddr: 10.0.23.3, DHCP siaddr: 0.0.0.0, DHCP giaddr: 10.0.23.2, DHCP chaddr: aabb.cc00.8000 *Dec 5 09:22:19.803: DHCP_SNOOPING: message type : DHCPREQUEST DHCP ciaddr: 0.0.0.0, DHCP yiaddr: 0.0.0.0, DHCP siaddr: 0.0.0.0, DHCP giaddr: 10.0.23.2, DHCP chaddr: aabb.cc00.8000 *Dec 5 09:22:19.804: DHCP_SNOOPING: message type : DHCPACK DHCP ciaddr: 0.0.0.0, DHCP yiaddr: 10.0.23.3, DHCP siaddr: 0.0.0.0, DHCP giaddr: 10.0.23.2, DHCP chaddr: aabb.cc00.8000
R3 receives the IP 10.0.23.3.
So not only is it necessary to define the port facing the DHCP server as trusted, it is also crucial do define the port facing the relay as a trusted port – both when traffic is sent upstream towards the DHCP server and downstream towards the DHCP client.
Packet Validation On Untrusted Ports
If any of the below checks match, the packet is dropped for untrusted ports:
- DHCP response packets (sent by the DHCP server)
- DHCPOFFER
- DHCPACK
- DHCPNAK
- Source MAC and DHCP Client hardware address does not match
- Only applicable when DHCP Snooping MAC address validation is turned on.
- ip dhcp snooping verify mac-address
- Only applicable when DHCP Snooping MAC address validation is turned on.
- A DHCPRELEASE or DHCPDECLINE is received on an interface that does not match the interface of the DHCP Snooping Binding table.
- A DHCP Packet is received and the giaddr (relay agent IP) is not 0.0.0.0 (non-zero)
To demonstrate the Source MAC validation check, we can enable the feature on SW1 and see what happens when R3 tries to release its IP:
! SW1 turn on DHCP Snooping MAC address validation: SW1(config)# SW1(config)#ip dhcp snooping verify mac-address SW1(config)#
The console log seen on SW1 when we shutdown the interface of R3 (creating a DHCPRELEASE):
! SW1 log: SW1# *Dec 5 09:43:25.486: %DHCP_SNOOPING-5-DHCP_SNOOPING_MATCH_MAC_FAIL: DHCP_SNOOPING drop message because the chaddr doesn't match source mac, message type: DHCPRELEASE, chaddr: aabb.cc00.8000, MAC sa: aabb.cc00.6000 SW1#
Regarding the giaddr check the Switch does, you can disable the verification of giaddr, but it creates another issues with the above topology:
! SW1 disable giaddr check: SW1(config)#no ip dhcp snooping verify no-relay-agent-address SW1(config)#
After this we see the following log on SW1:
! SW1 log output: SW1# *Dec 5 09:49:55.832: DHCP_SNOOPING: message type : DHCPOFFER DHCP ciaddr: 0.0.0.0, DHCP yiaddr: 10.0.23.5, DHCP siaddr: 0.0.0.0, DHCP giaddr: 10.0.23.2, DHCP chaddr: aabb.cc00.8000 *Dec 5 09:49:55.832: DHCP_SNOOPING_SW: client address lookup failed to locate client interface, retry lookup using packet mac DA: aabb.cc00.6000 SW1#
If we look at the packet as it comes in to SW1 from R1:
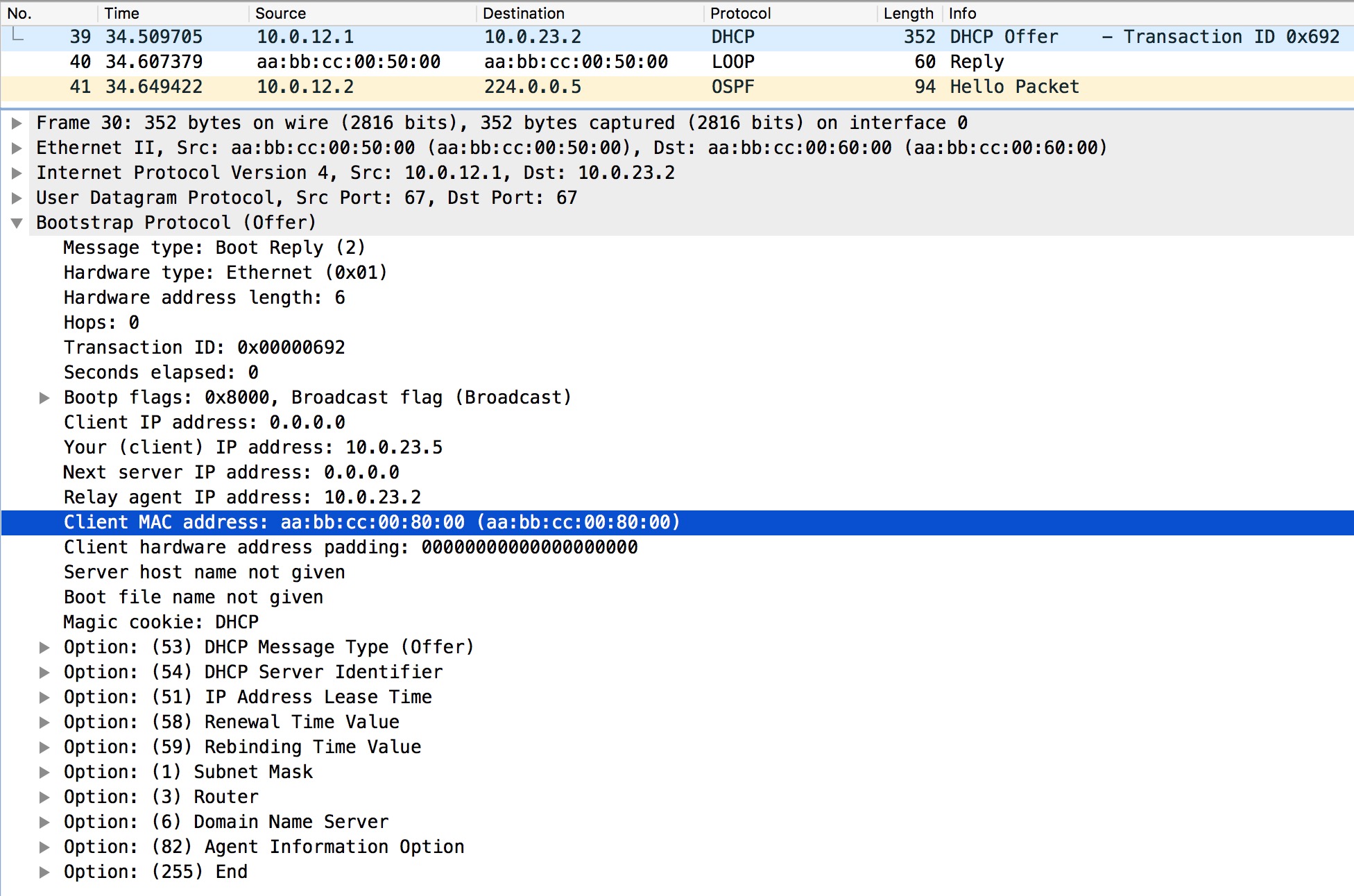
We have all the necessary information to be able to forward the packet to the relay agent (being a regular unicast packet), but the switch tries to lookup the client mac and fails. It does state that it will try to do a lookup using the packet mac destination address, but R3 never receives the Offer. Neither does R2, the relay agent. Making the switchport facing the relay agent trusted is really the only option here.
NTP
NTP (Network Time Protocol) is a way of distributing time to devices over a network. It uses UDP/123 for transport.
[table id=6 /]
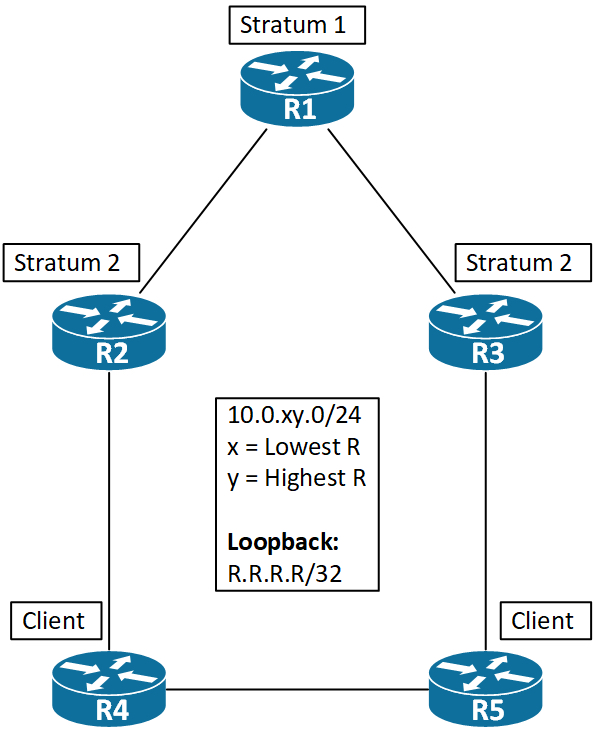
Stratum
Stratum is referring to how many hops you are away from an authoritative time source. The lower, the better. Stratum 1 is the “Root” that has its time from an atomic or GPS clock. Stratum ranges from 1 to 15. The default value is 8.
Server
By default any router is a NTP server. No configuration is required!
In the above topology we’ll set R1 to be the NTP Stratum 1 server. First we configure the clock locally on all routers. This ensures fast adjustment once we begin polling time from R1.
! R1 Stratum 1 configuration: R1#clock set 16:20:10 Nov 7 2017 R1#conf t Enter configuration commands, one per line. End with CNTL/Z. R1(config)#ntp master 1
Why must we then configure something on R1, if the NTP server requires no configuration? Well, since R1 does not have a valid source of time, we must tell it to be able to distribute time even though it is not synchronized to an existing time server. We make it an authoritative server using the ntp master command.
Let’s verify what happened:
! R1 Verification: R1#sh ntp status Clock is synchronized, stratum 1, reference is .LOCL. nominal freq is 250.0000 Hz, actual freq is 250.0000 Hz, precision is 2**10 ntp uptime is 28500 (1/100 of seconds), resolution is 4000 reference time is DDAC5BEB.1F7CEDE8 (16:20:59.123 UTC Tue Nov 7 2017) clock offset is 0.0000 msec, root delay is 0.00 msec root dispersion is 3939.44 msec, peer dispersion is 3938.29 msec loopfilter state is 'CTRL' (Normal Controlled Loop), drift is 0.000000000 s/s system poll interval is 16, last update was 12 sec ago. R1#
R1 now has its clock synchronized and is configured as a stratum 1 server. The reference clock I .LOCL. (local).
We can also see the NTP associations on R1:
! R1 NTP associations: R1#sh ntp associations address ref clock st when poll reach delay offset disp *~127.127.1.1 .LOCL. 0 4 16 377 0.000 0.000 1.204 * sys.peer, # selected, + candidate, - outlyer, x falseticker, ~ configured R1#
Here we see that R1 is associated to itself (127.127.1.1) which is the .LOCL. clock at stratum 0 (the reference clock).
In essence we’ve made R1 available as an authoritative NTP server for client devices.
Client
A client is configured by specifying the server from which you’d like time.
! R2 and R3: R2(config)#ntp source Loopback0 R2(config)#ntp server 1.1.1.1 R2(config)#
What happened? Let’s see:
! R2 debug ntp all: NTP message sent to 1.1.1.1, from interface 'Loopback0' (2.2.2.2). NTP message received from 1.1.1.1 on interface 'Loopback0' (2.2.2.2). NTP Core(DEBUG): ntp_receive: message received NTP Core(DEBUG): ntp_receive: peer is 0x7F347D4D8658, next action is 1. NTP Core(DEBUG): Peer becomes reachable, poll set to 6. NTP Core(INFO): 1.1.1.1 8014 84 reachable NTP Core(INFO): 1.1.1.1 962A 8A sys_peer NTP Core(NOTICE): Clock is synchronized.
And if we have a look at a capture of the packet being sent by R2 to poll R1:
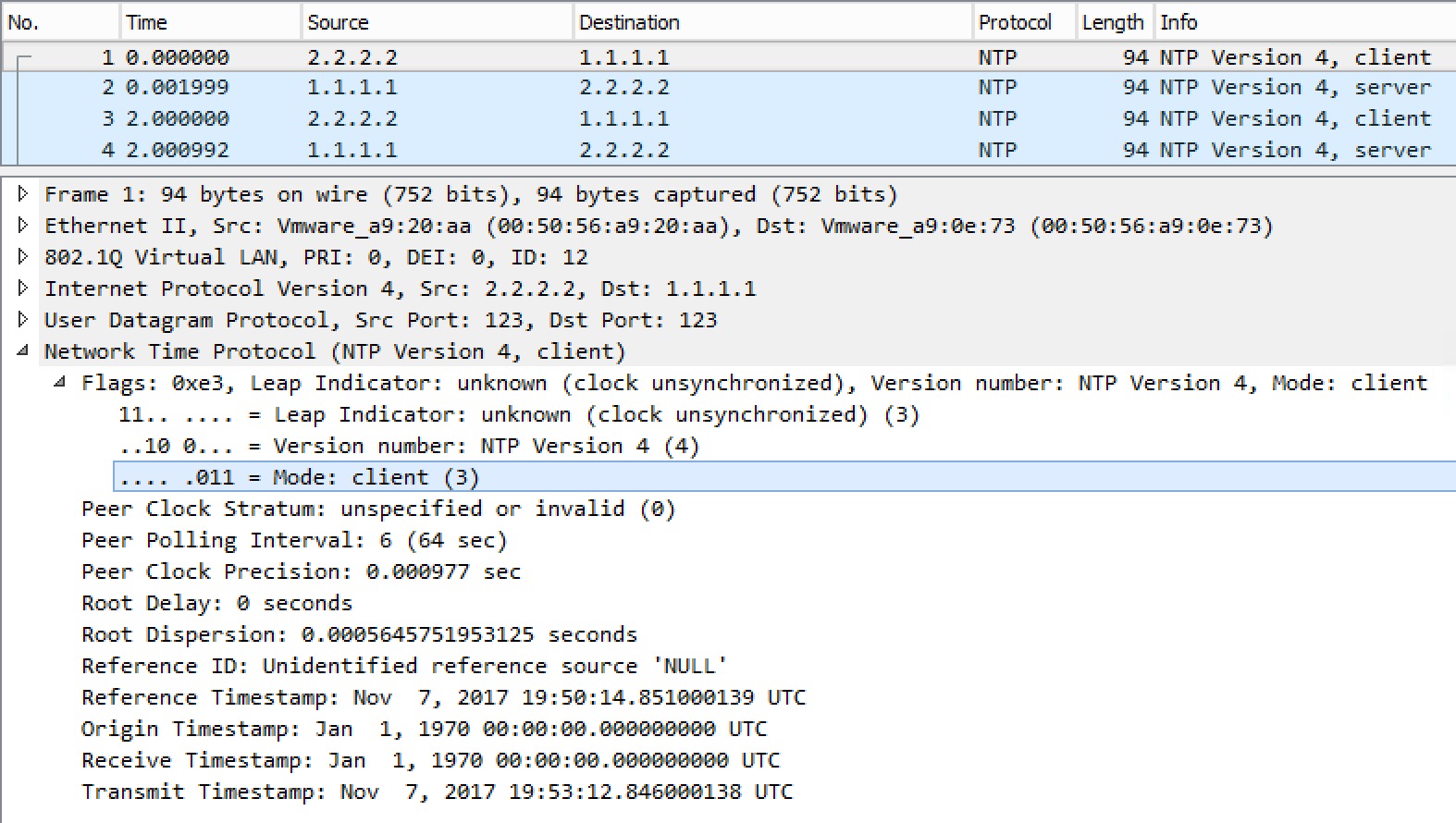
Off the bat we see that R2 runs NTP version 4. This is good as NTP version 4 is the newest version that also supports IPv6. It does not synchronize as fast as NTP version 3, though. We also see that R2 is currently unsynchronized and runs as a client.
And the reply from R1:
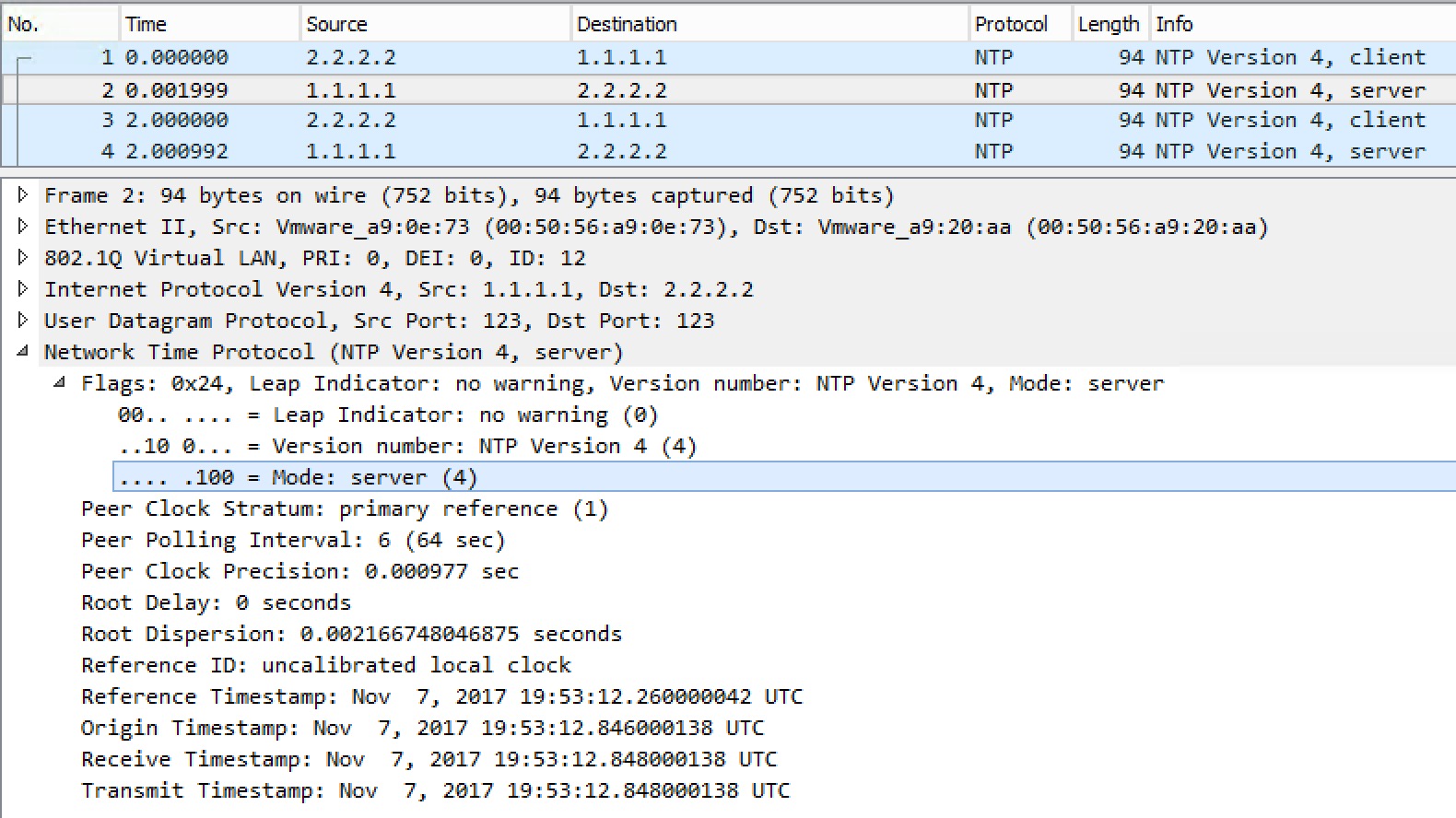
R1 replies saying it is the server. We also see the stratum (1). The Reference ID is the reference clock of R1.
Now that we’ve successfully received the time from R1, let’s see how R2 feels associated with R1:
! R2 ntp association: R2#sh ntp associations detail 1.1.1.1 configured, ipv4, our_master, sane, valid, stratum 1 ref ID .LOCL., time DDAC91D8.424DD3A8 (20:11:04.259 UTC Tue Nov 7 2017) our mode client, peer mode server, our poll intvl 128, peer poll intvl 128 root delay 0.00 msec, root disp 2.19, reach 377, sync dist 9.63 delay 2.00 msec, offset 0.0000 msec, dispersion 3.79, jitter 0.97 msec precision 2**10, version 4 assoc id 52963, assoc name 1.1.1.1 assoc in packets 23, assoc out packets 23, assoc error packets 0 org time 00000000.00000000 (00:00:00.000 UTC Mon Jan 1 1900) rec time DDAC91DA.D9168980 (20:11:06.848 UTC Tue Nov 7 2017) xmt time DDAC91DA.D9168980 (20:11:06.848 UTC Tue Nov 7 2017) filtdelay = 4.00 2.00 4.00 3.00 4.00 2.00 3.00 3.00 filtoffset = 0.00 0.00 -1.00 -0.50 1.00 0.00 -0.50 -0.50 filterror = 1.95 1.98 3.90 3.93 5.86 5.89 7.89 7.92 minpoll = 6, maxpoll = 10 R2#
And the status of R2:
! R2 ntp status: R2#sh ntp status Clock is synchronized, stratum 2, reference is 1.1.1.1 nominal freq is 250.0000 Hz, actual freq is 250.0000 Hz, precision is 2**10 ntp uptime is 1282200 (1/100 of seconds), resolution is 4000 reference time is DDAC94FD.D9999BF0 (20:24:29.850 UTC Tue Nov 7 2017) clock offset is 1.0000 msec, root delay is 3.00 msec root dispersion is 11.38 msec, peer dispersion is 3.02 msec loopfilter state is 'CTRL' (Normal Controlled Loop), drift is -0.000000023 s/s system poll interval is 128, last update was 311 sec ago. R2#
The clock is synchronized.
Peer
NTP has a peer function that makes a router synchronize to/from other peer routers. As long as the peers have the same stratum, they’ll synchronize each other. This provides redundancy. I think about it a bit in the same way as I think about iBGP peers. If a router looses its time from its primary source, it will still be able to serve correct time to clients, because it peers with another router who has a valid source.
This mode is also called Symmetric Active.
Let’s configure R2 and R3 as NTP peers:
! R2 and R3 NTP peer configuration: R2(config)#ntp peer 3.3.3.3 R2(config)# R3(config)#ntp peer 2.2.2.2 R3(config)#
And if we look at a capture:
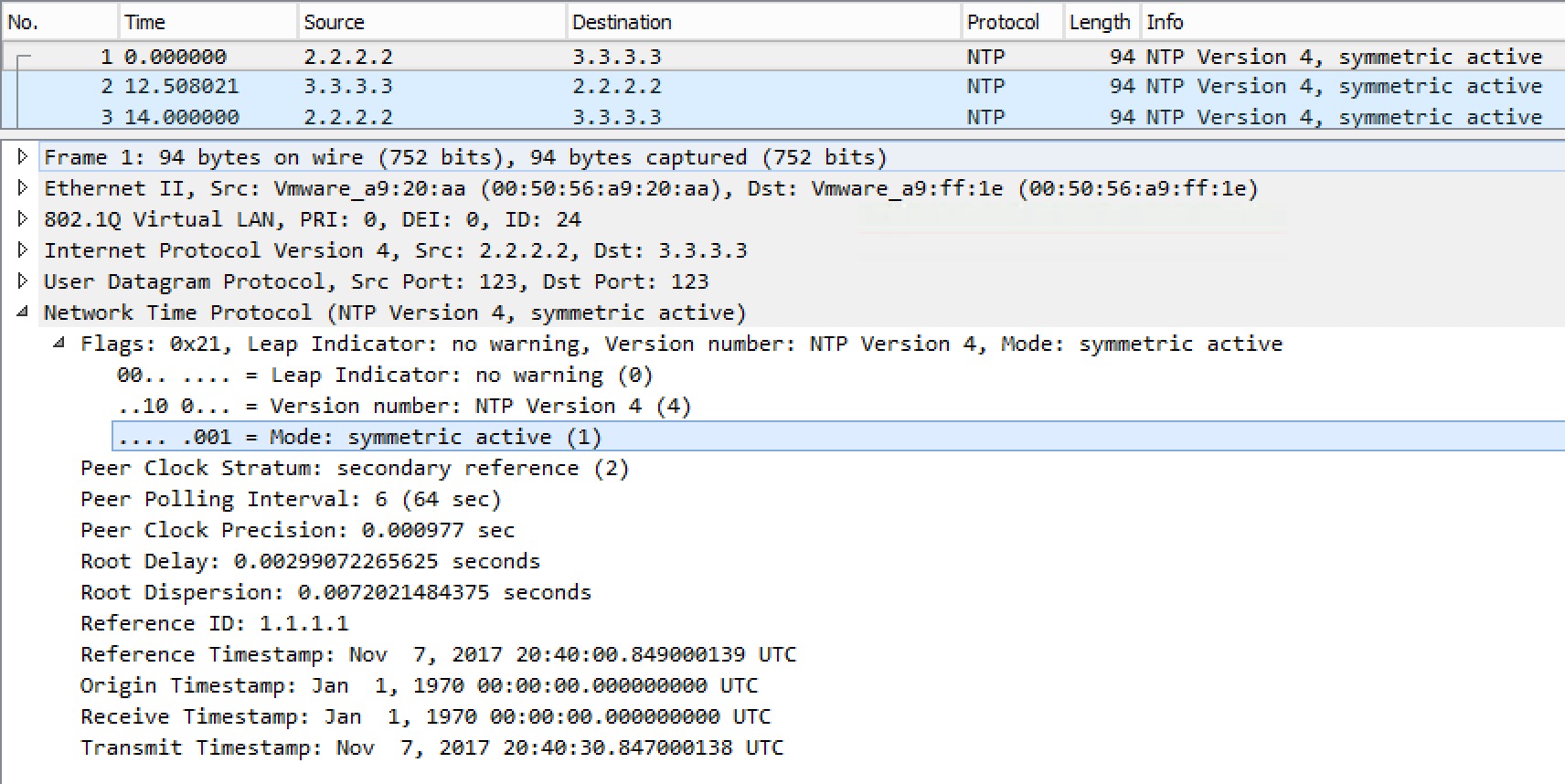
Here we see the symmetric active mode. Both R2 and R3 actively polls each other.
Access List
With NTP you have several options for controlling who can access your NTP implementation and how.
[table id=7 /]
Control messages are used instead of SNMP to obtain NTP information. I’ll not go into further details here. Please see RFC 1305 for more information.
Of the four options, only the top three are of interest. And out of the three only the peer option makes it possible for the local system to be updated with time information from other sources.
If we build on the example with R2 and R3 peering with each other, we can use an ACL to ensure that only R2 and R3 can peer – even if someone accidentally misconfigures or adds a peer.
! R2 and R3 NTP peer ACL: R2(config)#access-list 1 permit 3.3.3.3 R2(config)#ntp access-group peer 1 R2(config)# R3(config)#access-list 1 permit 2.2.2.2 R3(config)#ntp access-group peer 1 R3(config)#
If we debug ntp all after configuration on R2, we see:
! R2 debug ntp all output: NTP message received from 1.1.1.1 on interface 'Loopback0' (2.2.2.2). NTP Core(DEBUG): ntp_receive: message received NTP Core(NOTICE): ntp_receive: dropping message: restricted..
Ups! Remember the function of the peer ACL option? To list devices that we can synchronize with. Devices that can update our time. R1 is our stratum 1 server and we just made it impossible for it to keep providing time to R2 and R3!
! R2 and R3 fix NTP peer ACL: R2(config)#access-list 1 permit 1.1.1.1 R3(config)#access-list 1 permit 1.1.1.1
Now R2 and R3 can be synchronized by each other, and R1.
Note! If you configure a NTP ACL for one of the options (say peer) and you use other option (say serve), you must also configure a NTP ACL for the serve option! If one option is configured, all the other options are denied.
Broadcast
The NTP broadcast option was added in NTP version 3. Here you configure the server to broadcast the time information and the client to receive and listen to this broadcast. In our topology we can configure R2 as the NTP broadcast server and R4 as the NTP broadcast client:
! R2 NTP broadcast configuration: R2(config)#int gi1.24 R2(config-subif)#ntp broadcast R2(config-subif)#
! R4 NTP broadcast client configuration: R4(config)#int gi1.24 R4(config-subif)#ntp broadcast client R4(config-subif)#
Even though you can specify a NTP source interface globally, this will not be used in this mode. The source will always be that of the configured interface.
The problem with broadcast is that it is contained to the local subnet and not routed beyond that. We can of course fix this by using directed broadcast. With directed broadcast, instead of using the all broadcast address (255.255.255.255), you specify the subnets broadcast address, 10.0.24.255 for the subnet between R2 and R4 in this case. You can actually define multiple broadcast destination addresses along with the standard broadcast configuration on the server:
! R2 NTP broadcast destination configuration: R2(config)#int gi1.24 R2(config-subif)#ntp broadcast destination 10.0.45.255 R2(config-subif)#
Here we’ve specified the subnet broadcast destination for the link between R4 and R5. But because directed broadcasts are disabled by default on interfaces, we must enable it on the Gi1.45 link on R4 to make R4 forward it out that link.
! R4 enable directed broadcast: R4(config)#int gi1.45 R4(config-subif)#ip directed-broadcast
Now R5 must of course also be configured to receive and process the NTP broadcast messages:
! R5 NTP broadcast client: R5(config)#int gi1.45 R5(config-subif)#ntp broadcast client
That’s it for NTP broadcast. A more efficient way of doing this in a larger scale is to use NTP multicast.
Multicast
Like NTP broadcast you can configure NTP multicast. It is configured roughly the same way as NTP broadcast, but with a few more options.
! R2 NTP multicast configuration: R2(config)#int gi1.24 R2(config-subif)#ntp multicast R2(config-subif)#
If we debug this on R2, we get this information:
! R2 debug ntp all: Nov 7 21:48:14.847: NTP message sent to 224.0.1.1, from interface 'GigabitEthernet1.24' (10.0.24.2). Nov 7 21:48:14.847: NTP IPv4 multicast message discarded: not an NTP multicast client for 224.0.1.1
So with no options, the router uses the well-known multicast address 224.0.1.1 for NTP. We can of course also specify the group we want multicast to be sent to:
! R2 NTP multicast group: R2(config)#int gi1.24 R2(config-subif)#ntp multicast 224.2.2.2 R2(config-subif)#
This does require you to configure multicast routing in your network. Let’s assume that we’re running PIM sparse mode (because nobody sane would run dense mode). We must have a RP (Rendezvous Point) when running ASM (Any Source Multicast), because the source is not known to the receivers. I’ve configured R2 and R3 as RPs and configured PIM sparse mode on all interfaces.
Let’s try to configure R4 as a NTP multicast client of its Loopback0 interface:
! R4 NTP Multicast client configuration: R4(config-subif)#int lo0 R4(config-if)#ntp multicast client 224.2.2.2
If we debug ntp all on R4, we get this:
! R4 debug ntp all: R4# NTP IPv4 multicast message discarded: not an NTP multicast client for 224.2.2.2 R4#
Not what we expected! Let’s see the state of MC (Multicast):
! R4 IGMP groups joined: R4#sh ip igmp group IGMP Connected Group Membership Group Address Interface Uptime Expires Last Reporter Group Accounted 224.2.2.2 Loopback0 00:01:32 00:02:11 4.4.4.4 224.0.1.1 GigabitEthernet1.24 00:40:47 00:02:57 10.0.24.2 224.0.1.40 GigabitEthernet1.24 00:40:49 00:01:58 10.0.24.4 R4#
A debug on R2 shows this:
! R2 debug ntp all: R2# Nov 8 09:27:33.847: NTP message sent to 224.2.2.2, from interface 'Loopback0' (2.2.2.2). Nov 8 09:27:33.847: NTP IPv4 multicast message discarded: not an NTP multicast client for 224.2.2.2 R2#
The state on R2 (the RP):
! R2 mroute table:
R2#sh ip mroute 224.2.2.2 | be \(
(*, 224.2.2.2), 00:25:43/00:02:54, RP 2.2.2.2, flags: SJCL
Incoming interface: Null, RPF nbr 0.0.0.0
Outgoing interface list:
GigabitEthernet1.24, Forward/Sparse, 00:02:50/00:02:54
Loopback0, Forward/Sparse, 00:25:43/00:02:21
(2.2.2.2, 224.2.2.2), 00:25:42/00:03:02, flags: LT
Incoming interface: Loopback0, RPF nbr 0.0.0.0
Outgoing interface list:
GigabitEthernet1.24, Forward/Sparse, 00:02:50/00:02:54
R2#
I guess you can’t use a Loopback interface for the NTP multicast client feature! Let’s configure the Gi1.24 as a NTP multicast client on R4:
! R4 Gi1.24 NTP multicast client: R4(config)#int gi1.24 R4(config-subif)# ntp multicast client 224.2.2.2 R4(config-subif)#
And the debug output on R4:
! R4 debug ntp all: R4# NTP message received from 2.2.2.2 on interface 'GigabitEthernet1.24' (224.2.2.2). NTP Core(DEBUG): ntp_receive: message received NTP Core(DEBUG): ntp_receive: peer is 0x00000000, next action is 6. NTP message sent to 2.2.2.2, from interface 'GigabitEthernet1.24' (10.0.24.4). NTP message received from 2.2.2.2 on interface 'GigabitEthernet1.24' (10.0.24.4). NTP Core(DEBUG): ntp_receive: message received NTP Core(DEBUG): ntp_receive: peer is 0x7FCA5B2BA680, next action is 1. NTP Core(DEBUG): Peer bec R4#omes reachable, poll set to 6. NTP Core(INFO): 2.2.2.2 0014 84 reachable NTP Core(INFO): 2.2.2.2 162A 8A sys_peer NTP Core(NOTICE): trans state : 5 NTP Core(NOTICE): Clock is synchronized. R4# R4# R4#sh ntp associations address ref clock st when poll reach delay offset disp * 2.2.2.2 1.1.1.1 2 21 64 1 3.000 0.500 7938.4 * sys.peer, # selected, + candidate, - outlyer, x falseticker, ~ configured R4# R4#sh ntp status Clock is synchronized, stratum 3, reference is 2.2.2.2 nominal freq is 250.0000 Hz, actual freq is 250.0000 Hz, precision is 2**10 ntp uptime is 6300 (1/100 of seconds), resolution is 4000 reference time is DDAD4DBE.D22D1098 (09:32:46.821 UTC Wed Nov 8 2017) clock offset is 0.5000 msec, root delay is 4.99 msec root dispersion is 7956.21 msec, peer dispersion is 7938.47 msec loopfilter state is 'CTRL' (Normal Controlled Loop), drift is 0.000000000 s/s system poll interval is 64, last update was 32 sec ago. R4#
Finally!
Let’s have a look at the capture of the NTP multicast messages:
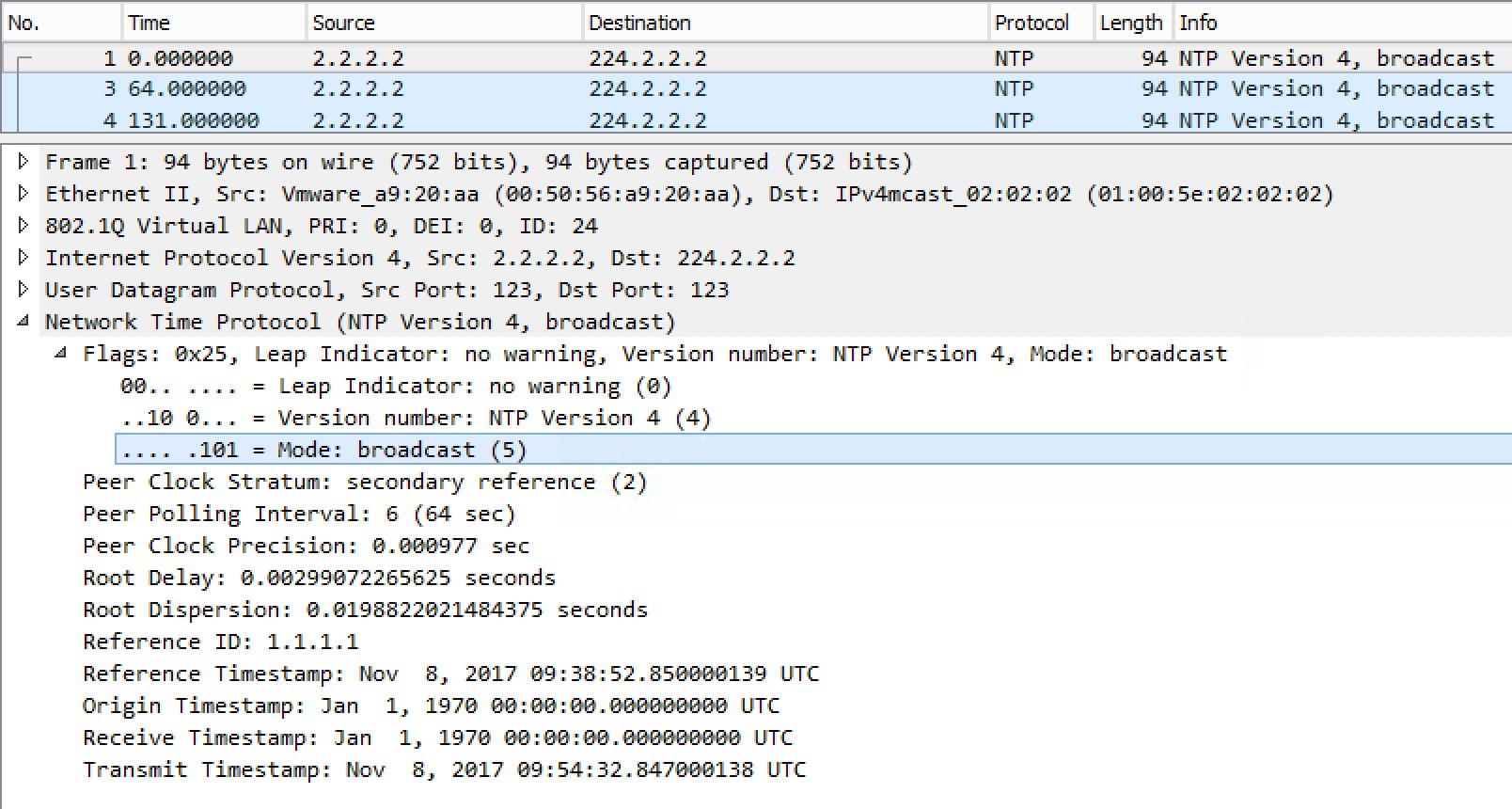
Notice the mode is broadcast! Other than that everything is the same as we’ve seen before.
With NTP multicast you have the option to limit the scope of the multicast packets by using TTL when sending out the packets. This is controlled by the server.
! R2 NTP Multicast scoping: R2(config)#int lo0 R2(config-if)# ntp multicast 224.2.2.2 ttl 1 R2(config-if)#
This should set TTL to 1 when sending multicast ntp to 224.2.2.2, but if we look at this capture taken on R4, this is not the case:
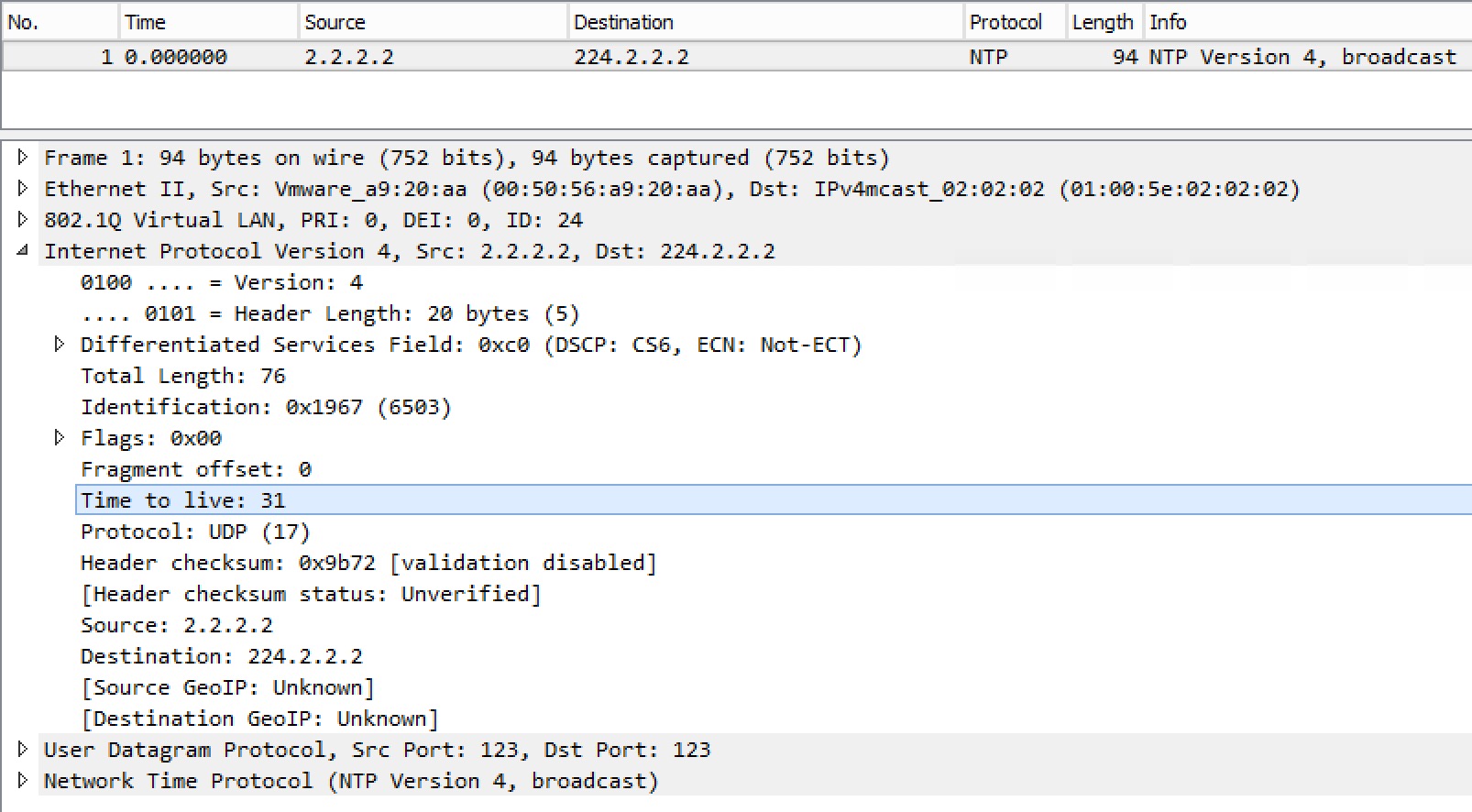
TTL is 31!
What about SSM (Source Specific Multicast)? Well, since we can’t specify a source when configuring the NTP multicast client feature, we must statically join the group on the interface on the client.
! R4 NTP multicast client using SSM: R4(config)#ip pim ssm default R4(config)# R4(config)#int gi1.24 R4(config-if)#ip igmp join-group 232.2.2.2 source 2.2.2.2 R4(config-if)# ip igmp version 3 R4(config-if)# ntp multicast client 232.2.2.2
First we specify the SSM range using the default range which is 232.0.0.0/8. It ensures co-existence with ASM by telling the router not to send (*,G) Joins for the ssm range. And since IGMPv2, which is the default version on interfaces, does not allow specifying a source, we must use IGMPv3.
Authentication
With NTP authentication you authenticate the source of time, meaning the server packets. This implies that the server sends out packets with a key ID and a hash that the clients then can validate.
! R4 NTP authentication configuration: R4(config)#ntp authentication-key 2 md5 cisco R4(config)#ntp trusted-key 2 R4(config)#ntp server 2.2.2.2 key 2
So we specify the authentication key ID 2 using MD5 and a string of Cisco. Next we must trust key ID 2 and attach the key ID to the ntp server.
If we debug ntp all on R4, we see:
! R4 debug ntp all: R4# NTP message sent to 2.2.2.2, from interface 'Loopback0' (4.4.4.4). NTP message received from 2.2.2.2 on interface 'Loopback0' (4.4.4.4). NTP Core(DEBUG): ntp_receive: message received NTP Core(DEBUG): ntp_receive: peer is 0x7FCA5B2BA680, next action is 1. NTP Core(INFO): 2.2.2.2 C01C 8C bad_auth crypto_NAK R4#
This is because we haven’t configured R2 to send the key requested by R4.
! R2 NTP authentication configuration: R2(config)#ntp authentication-key 2 md5 cisco R2(config)#ntp trusted-key 2
Like on the client we must specify the authentication key and also make this key trusted to be used.
Looking at the captures, we can see the Key IDs. First the packet from R4 polling R2:
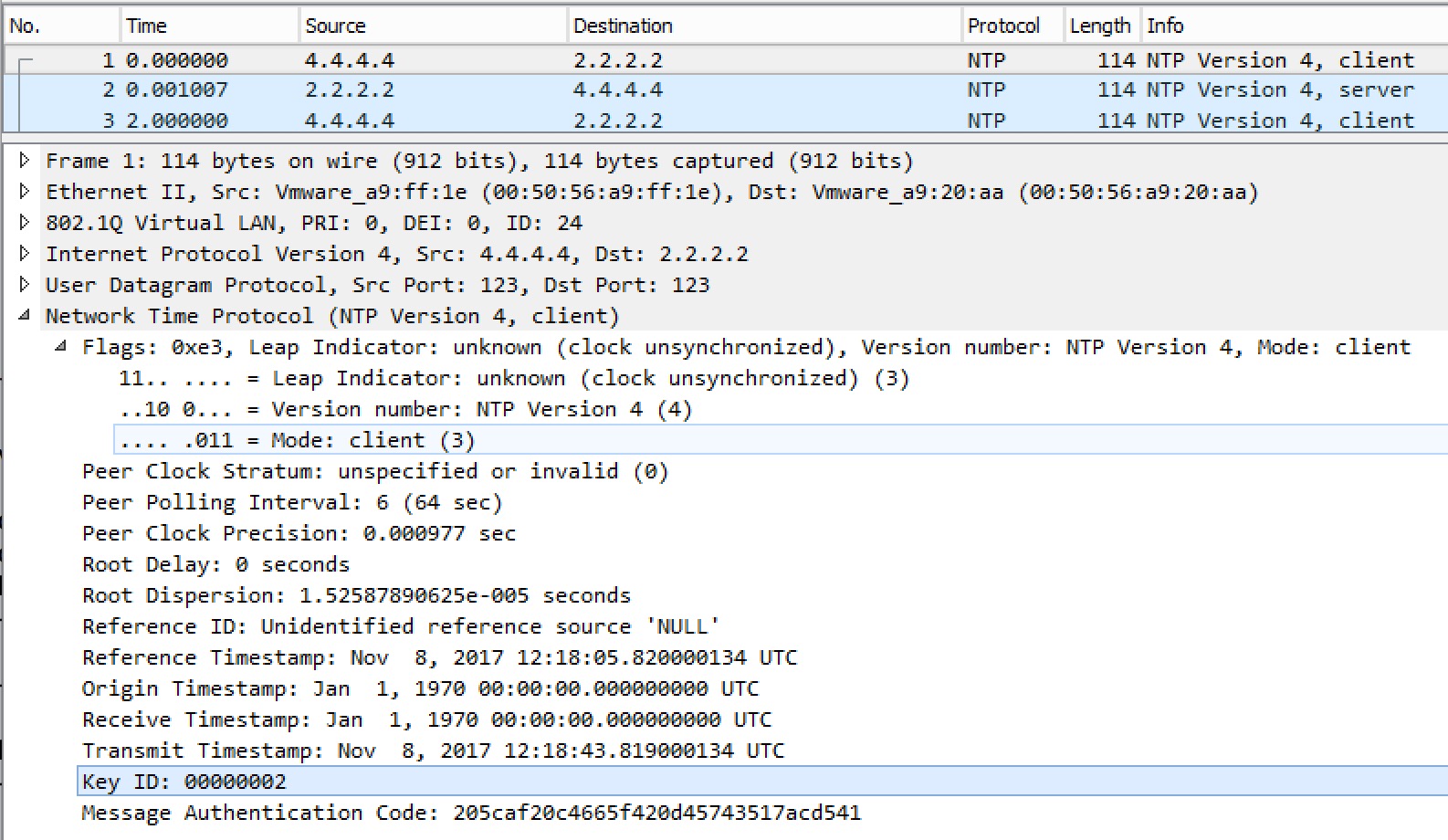
Next the reply from the server, R2:
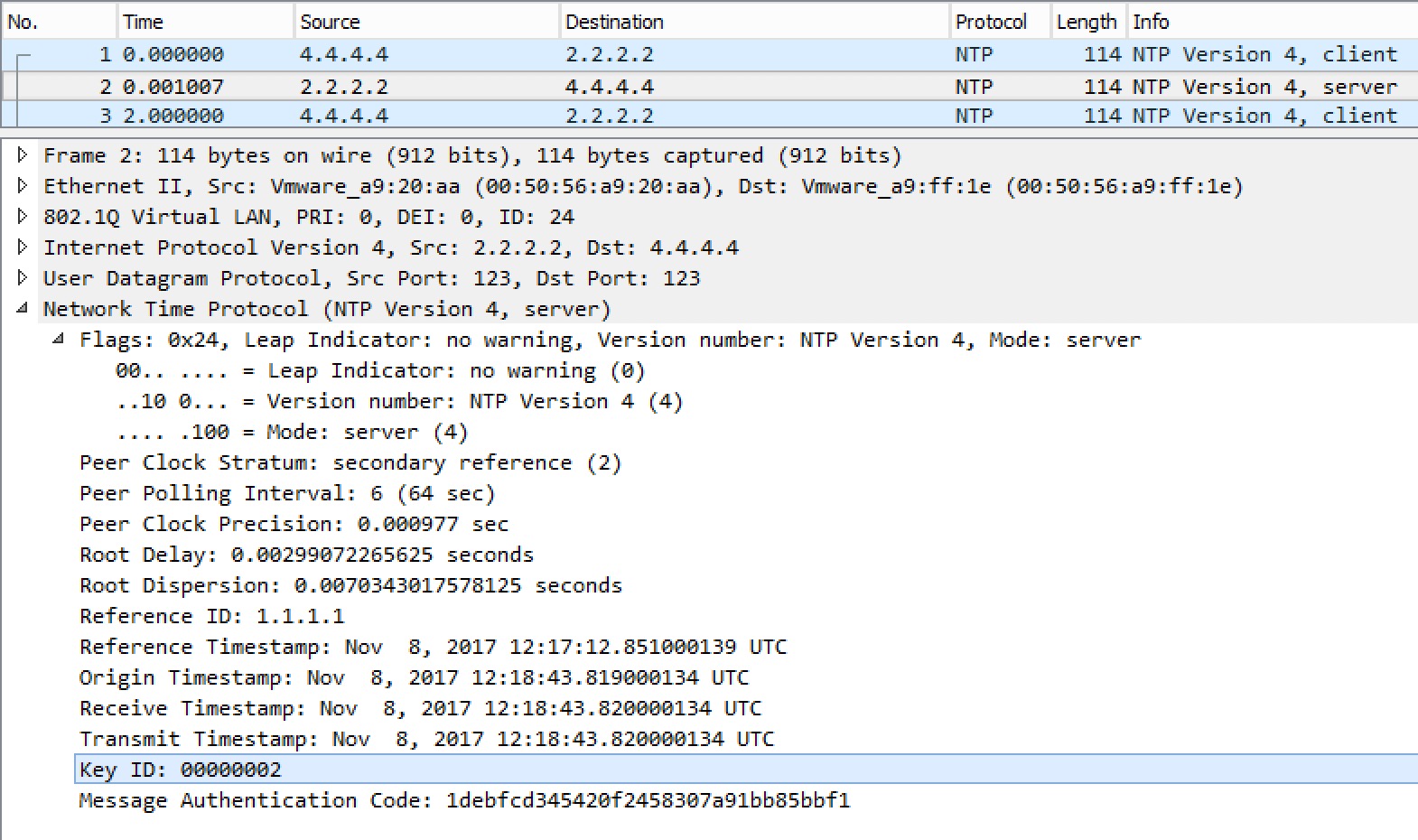
And verification on R4:
! R4 NTP authentication verification: R4#sh ntp associations detail 2.2.2.2 configured, ipv4, authenticated, our_master, sane, valid, stratum 2 ref ID 1.1.1.1 , time DDAD7448.D9DB2528 (12:17:12.851 UTC Wed Nov 8 2017) our mode client, peer mode server, our poll intvl 64, peer poll intvl 64 root delay 2.99 msec, root disp 10.07, reach 17, sync dist 17.61 delay 1.00 msec, offset 0.5000 msec, dispersion 3.71, jitter 0.97 msec precision 2**10, version 4 assoc id 65309, assoc name 2.2.2.2 assoc in packets 9, assoc out packets 9, assoc error packets 0 org time 00000000.00000000 (00:00:00.000 UTC Mon Jan 1 1900) rec time DDAD756E.D1A9FE28 (12:22:06.819 UTC Wed Nov 8 2017) xmt time DDAD756E.D1A9FE28 (12:22:06.819 UTC Wed Nov 8 2017) filtdelay = 2.00 1.00 2.00 1.00 2.00 2.00 2.00 1.00 filtoffset = 0.00 0.50 0.00 0.50 0.00 0.00 1.00 0.50 filterror = 1.95 2.95 3.96 4.84 4.87 4.90 4.93 4.96 minpoll = 6, maxpoll = 10 R4#
Here we see that 2.2.2.2 is authenticated.
NAT
To understand how NAT works it is imperative that we establish a foundation by defining the terms used when doing NAT.
[table id=9 /]
NAT Order of Operation
Cisco has a great document that shows the NAT Order of Operation. It does not explain why you route first before NAT (inside to outside) or why you NAT before routing (outside to inside).
Inside to Outside
The reason why the router must do a route lookup before it can do NAT is that it needs to know whether to do NAT at all. It does a route lookup and finds the exit interface for which you have a NAT statement. Now the router knows it must do NAT if the source qualifies.
Outside to Inside
The return traffic coming from outside to inside must first be NATted to be able to route to the Inside Local addresses.
Static NAT
Below is a topology explaining how the IP header addresses change when a packet is sent from a client (R1) on our local network to a server (WEB) Â on the global network.
The use case could be a cloud app where you have a local dns entry, but you get routed to the cloud app.
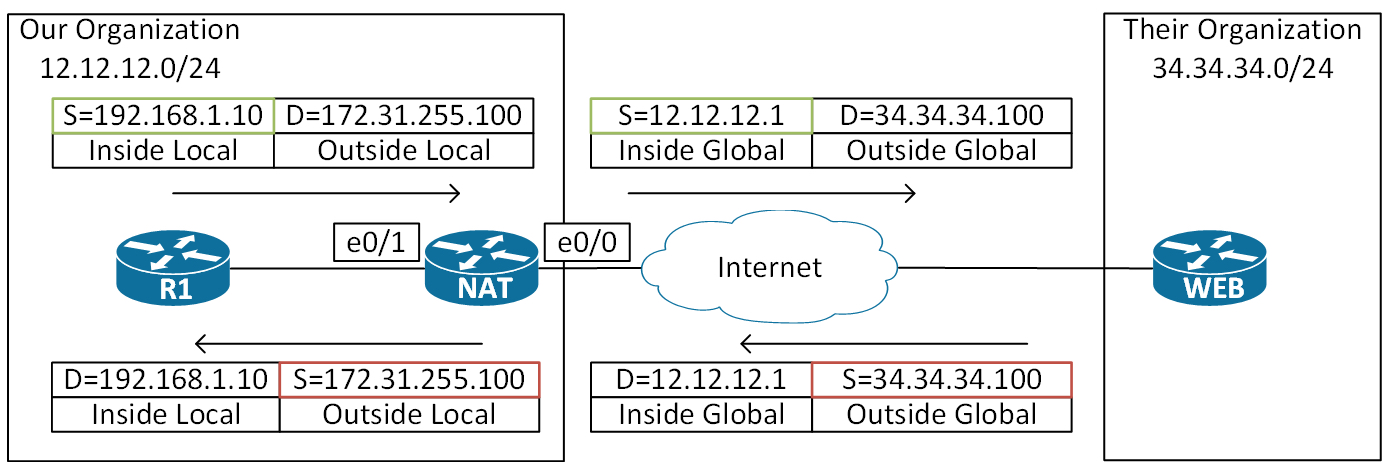
Here we see that inside our organization we only use Local definitions (Inside Local and Outside Local). These are addresses routable within our organization. Outside our organization – on the Internet – all addresses are public. Here we use the Global definitions (Inside Global and Outside Global).
From the perspective of the inside network, the outside addresses are the destinations we want to reach (DNAT). In contrast, the inside addresses are the sources we use (SNAT).
[table id=10 /]
Let’s have a look at the configuration:
! NAT router configuration NAT(config)#interface e0/0 NAT(config-if)#ip nat outside NAT(config-if)#interface e0/1 NAT(config-if)#ip nat inside NAT(config-if)#exit NAT(config)#ip nat inside source static 192.168.1.10 12.12.12.1 NAT(config)#ip nat outside source static 34.34.34.100 172.31.255.100 add-route
First of all notice that we’re only concerned with the sources in this configuration. I’ve highlighted the Inside sources in Green and the Outside sources in Red in the above topology. When configuring static NAT you think of the sources of the IP header from the perspective of the inside or outside network. For example, as the reply comes in from the outside, the source is the Outside Global (34.34.34.100) address. This will be translated into the Outside Local address (172.31.255.100). In other words, the translated address is always the last address you type in – regardless of whether we’re doing inside or outside NAT.
Because we’re using a fictitious destination address on R1 (the Outside Local address 172.31.255.100) we must add a route to it on the NAT router. The reason is that the NAT router does a route lookup before translating the destination when going from inside to outside. This is basic NAT Order of Operation. Without the keyword add-route, the NAT router would simply drop the packet and send back an ICMP unreachable reply to R1, like this:
! R1 debug ip icmp: *Nov 16 10:57:06.831: ICMP: dst (192.168.1.10) host unreachable rcv from 192.168.1.1
After the keyword add-route has been configured on the NAT router, we see this in the routing table of the NAT router:
! NAT routers route to 172.31.255.100 after add-route keyword:
NAT#sh ip route 172.31.255.100
Routing entry for 172.31.255.100/32
Known via "static", distance 1, metric 0
Routing Descriptor Blocks:
* 34.34.34.100
Route metric is 0, traffic share count is 1
NAT#
Finally we can verify the NAT translations table:
! NAT router translation table: NAT#sh ip nat translations Pro Inside global Inside local Outside local Outside global --- --- --- 172.31.255.100 34.34.34.100 --- 12.12.12.1 192.168.1.10 --- --- NAT#
To test, we can turn on debugging of NAT on the NAT router and ping 172.31.255.100 from R1:
! NAT router debug ip nat: NAT#debug ip nat IP NAT debugging is on NAT# NAT*: s=192.168.1.10->12.12.12.1, d=172.31.255.100 [38] NAT*: s=12.12.12.1, d=172.31.255.100->34.34.34.100 [38] NAT*: s=34.34.34.100->172.31.255.100, d=12.12.12.1 [38] NAT*: s=172.31.255.100, d=12.12.12.1->192.168.1.10 [38] NAT#
First we see the inside local source (192.168.1.10) being translated into the outside local source (12.12.12.1). Then the outside local destination (172.31.255.100) is being translated into the outside global destination (34.34.34.100). For the return traffic we reverse the translations.
Other uses cases for this kind of NAT would be a VPN where the remote end has overlapping IP addresses. And another one might be a migration of a server to a new IP address, but not all clients have been configured to use the new IP address and you want to ensure connectivity to both the new and old IP address of the server.
Alias
When the inside global or the outside local addresses belong to directly connected subnets, the router automatically creates an IP alias which makes it able to respond to ARP requests for these addresses.
Let’s have a look at a very simple topology for demonstrating this:
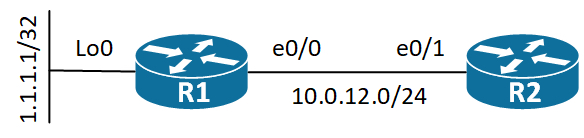
R1 will be the NAT router and R2 is just something we test against.
! R1 NAT configuration: R1(config)#int e0/0 R1(config-if)#ip nat outside R1(config-if)#int lo0 R1(config-if)#ip nat inside R1(config-if)#exit R1(config)#ip nat inside source static 1.1.1.1 10.0.12.100 R1(config)#
The above creates an inside source static NAT translation of the inside local address 1.1.1.1 to the inside global address 12.12.12.100 which is connected via e0/0 on R1.
By default the router creates an IP alias for the global addresses. Let’s verify:
! R1 alias verification: R1#sh ip alias Address Type IP Address Port Interface 1.1.1.1 Interface 12.1.1.1 Dynamic 10.0.12.100 R1#
As expected we see an alias for 10.0.12.100 and it is listed as a Dynamic address type. So let’s see how this comes to play when we issue a ping from R1s Lo0 to R2. We’ll enable some debugs of both NAT and ARP on R1.
! R1 debug NAT and ARP: R1#debug ip nat IP NAT debugging is on R1#debug arp ARP packet debugging is on R1#
Next we’ll do the ping:
! R1 ping R2:
R1#ping 10.0.12.2 source lo0 repeat 2
Type escape sequence to abort.
Sending 2, 100-byte ICMP Echos to 10.0.12.2, timeout is 2 seconds:
Packet sent with a source address of 1.1.1.1
NAT: s=1.1.1.1->10.0.12.100, d=10.0.12.2 [89]
IP ARP: rcvd req src 10.0.12.2 aabb.cc00.2210, dst 10.0.12.100 Ethernet0/0
IP ARP: sent rep src 10.0.12.100 aabb.cc00.1200,
dst 10.0.12.2 aabb.cc00.2210 Ethernet0/0.!
Success rate is 50 percent (1/2), round-trip min/avg/max = 1/1/1 ms
R1#
NAT: s=1.1.1.1->10.0.12.100, d=10.0.12.2 [90]
NAT*: s=10.0.12.2, d=10.0.12.100->1.1.1.1 [90]
R1#
First we see that our source 1.1.1.1 get translated to 10.0.12.100 as configured. Then we see that we receive an ARP request from 10.0.12.2 (R2) asking for the MAC address of 10.0.12.100. We reply and the the second packet of the ping is successful.
If we want we can disable the creation of the IP alias. Why would we want to to this? Well, besides allowing the router to respond to ARP requests when the translated address is routed via a connected interface, the IP aliases also makes the router reply to ICMP Echo requests. And we might want to remove the alias when doing NAT to translated addresses that are not reachable via a connected interface. If for example we do static PAT on R1 to allow R2 to access it via TCP/80:
! R1 Static PAT: R1(config)#ip http server R1(config)#ip http port 8080 R1(config)#ip nat inside source static tcp 1.1.1.1 8080 11.11.11.11 80 R1(config)#
If we ping the inside global IP Â (11.11.11.11) from R2, we receive a reply:
! R2 ping 11.11.11.11: R2#ping 11.11.11.11 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 11.11.11.11, timeout is 2 seconds: !!!!! Success rate is 100 percent (3/5), round-trip min/avg/max = 1/1/1 ms R2#
But if we configure the NAT with no-alias:
! R1 NAT with no-alias: R1(config)#ip nat inside source static tcp 1.1.1.1 8080 11.11.11.11 80 no-alias R1(config)# ! R2 ping 11.11.11.11: R2#ping 11.11.11.11 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 11.11.11.11, timeout is 2 seconds: U.U.U Success rate is 0 percent (0/5) R2#
We get ICMP Unreachable messages from R1. The NAT still works, though:
! R2 test web service on R1: R2#telnet 11.11.11.11 80 Trying 11.11.11.11, 80 ... Open CCIE HTTP/1.1 400 Bad Request Date: Thu, 16 Nov 2017 14:51:35 GMT Server: cisco-IOS Accept-Ranges: none 400 Bad Request [Connection to 11.11.11.11 closed by foreign host] R2#
If we are restricted to create aliases and still want to provide reachability, we can leverage the local proxy ARP feature on R1:
! R1 enable local proxy ARP: R1(config)#int e0/0 R1(config-if)#ip local-proxy-arp R1(config-if)#exit R1(config)#no ip nat inside source static tcp 1.1.1.1 8080 11.11.11.11 80 R1(config)#ip nat inside source static 1.1.1.1 10.0.12.100 no-alias
Local proxy ARP works by making the router respond to ARP requests for IP addresses on a connected subnet that is not configured on the router. Like 10.0.12.100 in this case.
! R2 ping 10.0.12.100: R2#ping 10.0.12.100 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 10.0.12.100, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms R2#
Despite having no alias on R1, we’re still able to ARP for 10.0.12.100 and obtain connectivity.
VRF-Aware NAT
I want to demonstrate how you do a simple NAT PAT when you have VRF-enabled interfaces. Let’s start by looking at the following topology:
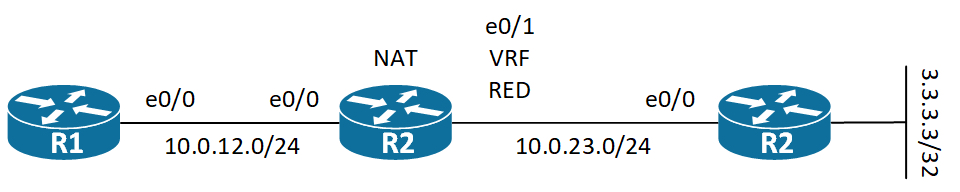
R2 is the NAT router and it has its e0/1 in VRF RED.
I would like to quote the description from Cisco Support Docs of the vrf keyword when doing NAT:
"Associates the NAT translation rule with a particular VPN routing and forwarding (VRF) instance."
This means that the vrf keyword relates to the source interface. Let’s configure NAT PAT on R2 to make R1 able to reach R3’s Lo0.
! R2 NAT configuration: R2(config)#ip route 0.0.0.0 0.0.0.0 Ethernet0/1 10.0.23.3 R2(config)#ip route vrf RED 10.0.12.0 255.255.255.0 10.0.12.1 global R2(config)# R2(config)#int e0/0 R2(config-if)#ip nat inside R2(config-if)#exit R2(config)#int e0/1 R2(config-if)#ip nat outside R2(config-if)#exit R2(config)# R2(config)#access-list 1 permit 10.0.12.0 0.0.0.255 R2(config)#ip nat inside source list 1 interface e0/1 overloadÂ
Remember the order of operation from inside to outside is first we route, then we NAT. The from outside to inside we do NAT first, then we route. So we need routing to be in place when dealing with VRFs. Specifically R1 needs to reach 3.3.3.3 in global. So I defined a default route pointing out e0/1 with next-hop 10.0.23.3 (R3). For the return traffic the router translates 10.0.23.2 back to 10.0.12.1 and then it routes. Therefore we must have a route in vrf RED back to 10.0.12.0/24 with the next-hop in global.
If we do a ping on R1 and look at the debug on R2:
! R2 debug ip nat and debug ip packet detail: R2# *Dec 5 12:41:59.959: FIBipv4-packet-proc: route packet from Ethernet0/0 src 10.0.12.1 dst 3.3.3.3 *Dec 5 12:41:59.959: FIBfwd-proc: packet routed by adj to Ethernet0/1 10.0.23.3 *Dec 5 12:41:59.959: FIBipv4-packet-proc: packet routing succeeded *Dec 5 12:41:59.959: NAT: s=10.0.12.1->10.0.23.2, d=3.3.3.3 [91] *Dec 5 12:41:59.960: NAT: s=3.3.3.3, d=10.0.23.2->10.0.12.1 [91] *Dec 5 12:41:59.961: FIBipv4-packet-proc: route packet from Ethernet0/1 src 3.3.3.3 dst 10.0.12.1 *Dec 5 12:41:59.961: FIBfwd-proc: packet routed by adj to Ethernet0/0 10.0.12.1 *Dec 5 12:41:59.961: FIBipv4-packet-proc: packet routing succeeded R2#
I’ve trimmed the output, but not touched the order of operation which is key in this output.
Now, what if we have the following topology:

Same situation as above, but now the VRF is defined on e0/0 of R2 and e0/1 is in global.
! R2 configuration of VRF-aware NAT: R2(config)#ip route vrf BLUE 0.0.0.0 0.0.0.0 10.0.23.3 global R2(config)#ip route 10.0.12.0 255.255.255.0 e0/0 10.0.12.1 R2(config)# R2(config)#int e0/0 R2(config-if)#ip nat inside R2(config-if)#exit R2(config)#int e0/1 R2(config-if)#ip nat outside R2(config-if)#exit R2(config)# R2(config)#ip nat inside source list 1 interface e0/1 vrf BLUE overload R2(config)#
Notice the vrf BLUE of the ip nat inside source command! This is what can be a bit confusing, because it relates to the inside interface and NOT e0/1 as one could imagine. Also the routing is fixed still using a default route for the forward traffic – this time in a VRF with the next-hop in global. And the reverse traffic is routed in global to the VRF by specifying the interface e0/0 and the next-hop of R1.
TCP Small Servers
[table id=4 /]
UDP Small Servers
[table id=5 /]