MPLS L3 VPN Walkthrough
Let me go over a basic MPLS L3 VPN using the topology below.
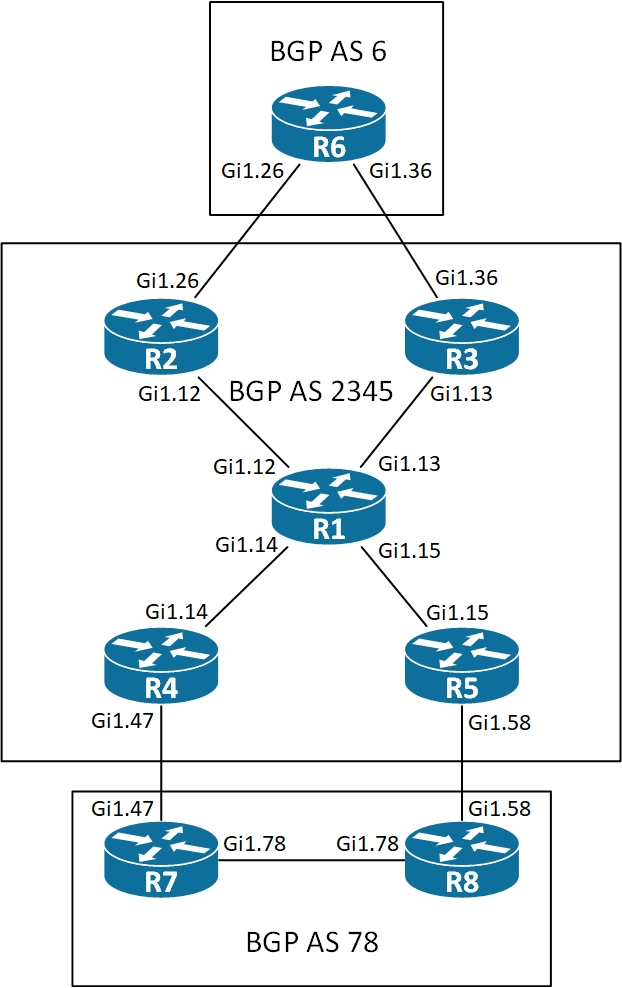
Here AS 2345 makes up the network that will provide the MPLS L3 VPN service to AS 6 and AS 78.
Building a MPLS L3 VPN service requires a couple of technologies for label exchange:
- MPLS – LDP
- BGP – VPNv4
For both LDP and BGP we need reachability of the loopback interfaces of the routers in AS 2345. I will go over the reason for this in a bit.
LDP
LDP (Label Distribution Protocol) is the protocol in charge of providing a transit label. It does so by having each router allocate a label for any IGP prefix it knows about and advertise those IP and label bindings to its neighbors. Let’s have a look at an example of this between R1 and R2.
! R1 config: interface Loopback0 ip address 1.1.1.1 255.255.255.255 ip ospf 1 area 0 ! interface GigabitEthernet1.12 encapsulation dot1Q 12 ip address 10.0.12.1 255.255.255.0 ip ospf network point-to-point ip ospf 1 area 0 mpls ip R1#
The configuration of R2 is very similar to that of R1 so I will not provide it to save space and avoid clutter.
Time for verification. We will look at it from R2’s perspective:
! R2 LDP verification:
R2#sh mpls ldp neighbor
Peer LDP Ident: 1.1.1.1:0; Local LDP Ident 2.2.2.2:0
TCP connection: 1.1.1.1.646 - 2.2.2.2.38200
State: Oper; Msgs sent/rcvd: 426/427; Downstream
Up time: 06:02:37
LDP discovery sources:
GigabitEthernet1.12, Src IP addr: 10.0.12.1
Addresses bound to peer LDP Ident:
10.0.12.1 10.0.13.1 10.0.14.1 10.0.15.1
1.1.1.1
R2#
We have a lot of interesting information here. First of all what you always must look for in this output is the Peer LDP Ident. This is the LDP router-id of the neighbor. By default this router-id is also used to establish the TCP session between the routers. This is one of the reasons why I wrote earlier that the loopback must be reachable.
Next very important thing to verify is the State. A state of Oper (Operational) means that everything is good.
Lastly the� Addresses bound to peer LDP Ident� section is very important. I will touch on this a bit later.
So far so good. Now let’s see which labels we have generated and received on R2.
! R2 Label bindings:
R2#sh mpls ldp bindings
lib entry: 1.1.1.1/32, rev 12
local binding: label: 19
remote binding: lsr: 1.1.1.1:0, label: imp-null
lib entry: 2.2.2.0/24, rev 20
local binding: label: imp-null
lib entry: 2.2.2.2/32, rev 21(no route)
no local binding
remote binding: lsr: 1.1.1.1:0, label: 19
lib entry: 3.3.3.3/32, rev 10
local binding: label: 18
remote binding: lsr: 1.1.1.1:0, label: 18
lib entry: 4.4.4.4/32, rev 8
local binding: label: 17
remote binding: lsr: 1.1.1.1:0, label: 17
lib entry: 5.5.5.5/32, rev 6
local binding: label: 16
remote binding: lsr: 1.1.1.1:0, label: 16
lib entry: 10.0.12.0/24, rev 2
local binding: label: imp-null
remote binding: lsr: 1.1.1.1:0, label: imp-null
lib entry: 10.0.13.0/24, rev 18
local binding: label: 22
remote binding: lsr: 1.1.1.1:0, label: imp-null
lib entry: 10.0.14.0/24, rev 16
local binding: label: 21
remote binding: lsr: 1.1.1.1:0, label: imp-null
lib entry: 10.0.15.0/24, rev 14
local binding: label: 20
remote binding: lsr: 1.1.1.1:0, label: imp-null
R2#
A lot of labels have been received for this small 5 router network! This is because every router generates labels for _ALL_ IGP prefixes. Even the once it just received labels for from its direct neighbor! This is why we for 1.1.1.1/32 see a local binding with label 19. This is somewhat analogous to how Distance Vector routing protocols. Unlike Distance Vector protocols LDP does not have split horizon, mening that R2 will advertise the binding for 1.1.1.1/32 right back at R1! You’ll see this below when looking a the binding on R1 for 1.1.1.1/32.
R1#sh mpls ldp bindings | be 1.1.1.1
lib entry: 1.1.1.1/32, rev 2
local binding: label: imp-null
remote binding: lsr: 4.4.4.4:0, label: 17
remote binding: lsr: 3.3.3.3:0, label: 18
remote binding: lsr: 5.5.5.5:0, label: 16
remote binding: lsr: 2.2.2.2:0, label: 19
! output omitted for brevity
So on R1 we receive label binding from all of our neighbors! Quite a bit of overhead with LDP. Why isn’t this an issue with loops then? Because of the way the labels are used in conjunction with the routing table. And it has to do with how a router decides which of all the binding labels to use. The router simply looks at the next-hop IP of a prefix, then it looks at the� Addresses bound to peer LDP Ident� from its LDP neighbors and see if there is a match. If one of them matches, the router knows the LDP Ident of the neighbor and can find the remote binding among all the label bindings it has learned. If for example we were to look at how R2 finds the correct label for reaching R3’s loopback using this method:
! R2 find NH to R3's loopback:
R2#sh ip route 3.3.3.3
Routing entry for 3.3.3.3/32
Known via "ospf 1", distance 110, metric 3, type intra area
Last update from 10.0.12.1 on GigabitEthernet1.12, 06:33:53 ago
Routing Descriptor Blocks:
* 10.0.12.1, from 3.3.3.3, 06:33:53 ago, via GigabitEthernet1.12
Route metric is 3, traffic share count is 1
R2#
Now we know that 10.0.12.1 is the NH to reach 3.3.3.3/32. Next let’s see if we can find this NH address among any of our LDP neighbors interfaces (Addresses bound to peer LDP Ident):
R2#sh mpls ldp neighbor | in Ident:|10.0.12.1_
Peer LDP Ident: 1.1.1.1:0; Local LDP Ident 2.2.2.2:0
GigabitEthernet1.12, Src IP addr: 10.0.12.1
Addresses bound to peer LDP Ident:
10.0.12.1 10.0.13.1 10.0.14.1 10.0.15.1
R2#
Bingo! We found the LDP Ident (1.1.1.1:0) of the neighbor who has 10.0.12.1 configured. Now we can look in the label binding tabel and find the label we must use when forwarding packets to 3.3.3.3/32 out Gi1.12:
R2#sh mpls ldp bindings 3.3.3.3 32
lib entry: 3.3.3.3/32, rev 10
local binding: label: 18
remote binding: lsr: 1.1.1.1:0, label: 18
R2#
And the remote binding for 3.3.3.3/32 from 1.1.1.1:0 is telling us to use label 18.
You can see all of this by looking in CEF:
R2#sh ip cef 3.3.3.3/32 3.3.3.3/32 nexthop 10.0.12.1 GigabitEthernet1.12 label 18 R2#
LDP Lingo
So far I have been using the term label binding table and stuff like that. Here is an overview of the various tables and their names:
- FIB – The regular CEF table as we all know it.
- sh ip cef
- LIB – This is what I called the label binding table. It is somewhat like the topology table of EIGRP or the LSDB of OSPF. Think of it as a label RIB.
- sh mpls ldp binding
- LFIB – This is the actual MPLS forwarding table containing the labels used for forwarding.
- sh mpls forwarding-table
BGP
Now that we know how LDP works and that it provides the transport labels needed for forwarding packets of our customers between the PE routers. We need a way of segmenting our customers which is the hole idea of MPLS L3 VPNs. This is where BGP comes into the picture. It too can allocate labels. These are the VPN labels used in the bottom of the label stack.
The VPNv4 BGP AFI is used for exchanging the prefixes between PE routers – either directly in smaller networks or through RRs. And for doing the segmentation we need something do distinguish the prefixes received from our customers. This is where route-targets (RTs) comes in. The RTs are attached to the prefixes using BGP extended communities. So we must enable sending of extended communities when we peer using VPNv4 AFI. RTs work by attaching the RT when exporting (from the Customer VRF to BGP) the prefix and on the remote PE we use the RT when importing (from BGP to the Customer VRF) the prefix. Now we also need a way of making all prefixes unique which allows for overlapping prefixes between customers. This is where the route distinguisher (RD) come is. This RD which is (of course) unique per VRF is prepended to the prefixes received from the customer and makes the prefix a VPNv4 prefix. Let’s have a look at all of this. First I will show the configuration of a VRF and BGP, then we’ll look at the verification putting the pieces together.
! R2 VRF config: vrf definition a rd 2.2.2.2:6 route-target export 2345:6 route-target import 2345:6 ! address-family ipv4 exit-address-family
Defining a VRF gives the ability to use it for both IPv4 and IPv6. If you create the VRF using the legacy� ip vrf� command, you’ll only have IPv4 capability. We define the RD and the RTs for importing and exporting prefixes.
Next we have the BGP config part.
R2#sh run | sec router bgp router bgp 2345 bgp log-neighbor-changes neighbor 5.5.5.5 remote-as 2345 neighbor 5.5.5.5 update-source Loopback0 ! address-family vpnv4 neighbor 5.5.5.5 activate neighbor 5.5.5.5 send-community extended exit-address-family ! address-family ipv4 vrf a neighbor 10.0.26.6 remote-as 6 neighbor 10.0.26.6 activate exit-address-family R2#
In BGP we first define the neighbor and how we establish a peering with them using the remote-as and update-source commands. With MPLS L3 VPNs the update-source is extremely important, because it is used as the NH on the remote PEs and for forwarding to work on Cisco routers it must be a /32 prefix used for the NH with MPLS L3 VPNs.
The neighbor is then activated under the VPNv4 AFI which in newer code also configured the sending of the extended community.
Lastly we have the peering to our customer in vrf a so we can import and export prefixes tying together the customers sites.
Let’s have a look at what we have received form the customer in VRF a:
R2#sh bgp vpnv4 u vrf a
BGP table version is 4, local router ID is 2.2.2.2
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
Route Distinguisher: 2.2.2.2:6 (default for vrf a)
*> 6.6.6.6/32 10.0.26.6 0 0 6 ?
R2#
We’ll drill down into 6.6.6.6/32:
R2#sh bgp vpnv4 u vrf a 6.6.6.6/32
BGP routing table entry for 2.2.2.2:6:6.6.6.6/32, version 2
Paths: (1 available, best #1, table a)
Advertised to update-groups:
1
Refresh Epoch 1
6
10.0.26.6 (via vrf a) from 10.0.26.6 (6.6.6.6)
Origin incomplete, metric 0, localpref 100, valid, external, best
Extended Community: RT:2345:6
mpls labels in/out 23/nolabel
rx pathid: 0, tx pathid: 0x0
R2#
So upon receiving the prefix from our customer in VRF a, we’ve attached the RD giving the VPNv4 prefix of 2.2.2.2:6:6.6.6.6/32 and the RT 2345:6. Also we’ve allocated the label 23 for this specific prefix. By default Cisco routers allocate a VPN label per prefix using this command:
mpls label mode all-vrfs protocol all-afs per-prefix
You could change this to be per-vrf or per-ce
A PE router that has no import RT matching those of the received VPNv4 prefixes will discard the updates. Let’s see this in action:
R4#deb bgp vpnv4 u updates BGP updates debugging is on for address family: VPNv4 Unicast R4#clear bgp vpnv4 u * in R4# BGP(4): 5.5.5.5 rcvd UPDATE w/ attr: nexthop 2.2.2.2, origin ?, localpref 100, metric 0, originator 2.2.2.2, clusterlist 5.5.5.5, merged path 6, AS_PATH , extended community RT:2345:6 BGP(4): 5.5.5.5 rcvd 2.2.2.2:6:6.6.6.6/32, label 23 -- DENIED due to: extended community not supported; R4#sh bgp vpnv4 u all 6.6.6.6/32 % Network not in table R4#
As we can see the update is DENIED (discarded) because we do not have the RT 2345:6 in any import statements under any VRFs.
This is true on all VPNv4 routers except RRs. It makes sense. How else are RRs to be able to reflect prefixes from PEs to other PEs? They have need for installing the customers prefixes. They just must reflect the prefixes which is why RRs will not deny VPNv4 updates, but hold them in the BGP table for further reflection.
AS Override
Let’s say a customer decides to build a template for the CE devices using the same ASN for all routers. This causes reachability issues when updates are received in on other sites, because of the AS_PATH loop prevention built in to BGP (rejecting prefixes containing our own AS). Two BGP features exist for preventing this issue. You can either use the allowas-in on the CE devices, or the SP can help by using the as-override feature.
The neighbor as-override command looks at prefixes before they are sent to the other sites of a customer (so on the egress PE node). It compares the AS_PATH to the remote-as configured for the neighbor. If they match, the ASN is overridden (replaced) with the AS of the SP before sending the update to the CE router.
If for example R6, R7, and R8 are in AS 78 and R6 sends an update for network 66.66.66.66/32 to the SP. This is of corse sent to R2 with 78 in the AS_PATH. The SP somehow forwards this update to the PE routers that will accept the update if they have an import statement under a VRF matching the extended community of the prefix. Let’s say R4 is the egress PE node we’re looking at. It will now check the remote-as configured for R7 comparing it to the AS_PATH of the prefix and overriding (replacing) any AS that matches that of the remote-as – even if R6 prepended its AS before sending it to R2. Let’s have a look at the prefix on R7:
R7#sh bgp 66.66.66.66/32
BGP routing table entry for 66.66.66.66/32, version 34
Paths: (2 available, best #2, table default)
Advertised to update-groups:
5
Refresh Epoch 1
2345 2345 66 2345
10.0.58.5 from 10.0.78.8 (8.8.8.8)
Origin IGP, metric 0, localpref 100, valid, internal
rx pathid: 0, tx pathid: 0
Refresh Epoch 2
2345 2345 66 2345
10.0.47.4 from 10.0.47.4 (4.4.4.4)
Origin IGP, localpref 100, valid, external, best
rx pathid: 0, tx pathid: 0x0
R7#
Here we see that R6 did a prepend of the 78 66 78. The 78 AS (configured for R7 on R4 using the remote-as command) has now been replaced with 2345 66 2345 and of course prepended with the SP AS before sending it to R7 making the AS_PATH complete with: 2345 2345 66 2345
BGP SoO
The as-override feature disables the AS_PATH loop prevention of BGP, because now the AS_PATH does not contain the receiving routes own AS. This� can� cause loops when a site is multi homed like R7 and R8 are in this case. This calls for another feature configured on the SP – BGP SoO (Site of Origin). Let’s see how this works.
router bgp 2345 ! address-family ipv4 vrf b neighbor 10.0.47.7 remote-as 78 neighbor 10.0.47.7 activate neighbor 10.0.47.7 as-override neighbor 10.0.47.7 soo 2345:78 exit-address-family R4#
Above is the BGP configuration for VRF b of R4. Here both as-override and SoO have been configured for R7. The SoO value must be the same on all PE routers that peer with this site (hence the name Site of Origin). When configured, BGP will check the SoO extended community value of a prefix and compare this value to the SoO value configured for the peer. If they match, the PE node will� not send this prefix to the peer and a loop is avoided. We can verify if prefixes are being denied due to SoO by looking at the neighbor:
R4#sh bgp vpnv4 u vrf b neighbors 10.0.47.7
! output omitted for brevity
Outbound Inbound
Local Policy Denied Prefixes: -------- -------
AS_PATH loop: n/a 7
SOO loop: 3 n/a
Bestpath from this peer: 8 n/a
Total: 11 7
#R4