Unified MPLS
Also known as seamless MPLS, or hierarchical MPLS. It’s a way to scale to a very large network with multiple IGP domains. Let’s get started exploring this feature.
I’ll use the below topology as we go along.
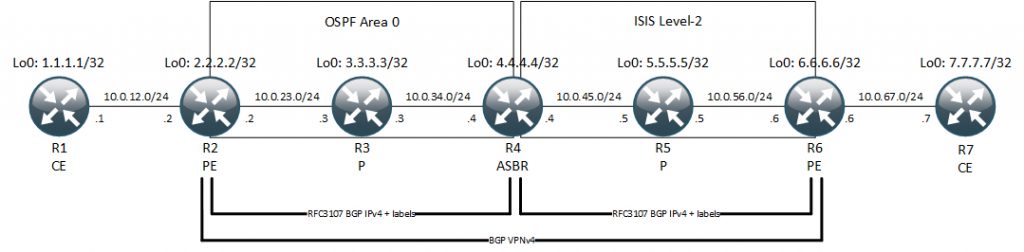
What’s new here is the RFC 3107 BGP IPv4 + label and the fact that we have multiple IGP domains. In this topology we have both an OSPF domain to the left between R2-R3-R4. Also to the right we have ISIS between R4-R5-R6.
We still have a VPNv4 peering between our PE routers which give us the NLRI for the customer prefixes along with a VPN label for these. So far so good. The glue between the PE routers is what makes up unified MPLS. So to get reachability between our PE routers without doing a full redistribution between our IGP domains, we use BGP IPv4 and make our ASBRs inline RRs. Additionally we set NH to the RRs. This is done because we keep the IGP domain separate and use BGP to allocate the label for transport of the egress PE’s loopback0 interface. In total, this builds up a hierarchical MPLS. We still need LDP in the IGP domains to provide a transport label between PE-ASBR and ASBR-ASBR (if we had any) and lastly ASBR-PE. The only thing that changes is that we need an extra label at our ingress PE. That’s how it works. Let’s have a look at the configuration and verification.
Configuration
! R2 (PE)
interface Loopback0
ip address 2.2.2.2 255.255.255.255
ip ospf 1 area 0
!
vrf definition a
rd 2.2.2.2:10
route-target export 65000:10
route-target import 65000:10
!
address-family ipv4
exit-address-family
!
mpls label range 200 299
mpls ldp router-id Loopback0 force
!
router ospf 1
router-id 2.2.2.2
mpls ldp autoconfig
!
router bgp 65000
bgp router-id 2.2.2.2
bgp log-neighbor-changes
no bgp default ipv4-unicast
neighbor 4.4.4.4 remote-as 65000
neighbor 4.4.4.4 update-source Loopback0
neighbor 6.6.6.6 remote-as 65000
neighbor 6.6.6.6 update-source Loopback0
!
address-family ipv4
network 2.2.2.2 mask 255.255.255.255
neighbor 4.4.4.4 activate
neighbor 4.4.4.4 send-label
exit-address-family
!
address-family vpnv4
neighbor 6.6.6.6 activate
neighbor 6.6.6.6 send-community extended
exit-address-family
!
address-family ipv4 vrf a
neighbor 10.0.12.1 remote-as 65001
neighbor 10.0.12.1 activate
exit-address-family
Beginning with our PE, R2. Everything is pretty standard until we reach the ipv4 address-family under BGP. Here we start being a bit uncomfortable if we’re used to regular MPLS VPNs. But nothing to worry about. We’re just using IPv4+labels to allocate a transport label for the PE loopbacks for use in the other IGP domains.
R3 I’m not going to show as it only has OSPF + LDP configured, so nothing new here.
R4 on the other hand have have lots of new stuff going on. Let’s look:
! R4 (ASBR/RR)
interface Loopback0
ip address 4.4.4.4 255.255.255.255
ip ospf 1 area 0
!
mpls ldp router-id Loopback0 force
mpls label range 400 499
!
router ospf 1
router-id 4.4.4.4
mpls ldp autoconfig
!
router isis
net 49.0001.0040.0400.4004.00
is-type level-2-only
advertise passive-only
metric-style wide
passive-interface Loopback0
mpls ldp autoconfig
!
router bgp 65000
bgp router-id 4.4.4.4
bgp log-neighbor-changes
no bgp default ipv4-unicast
neighbor 2.2.2.2 remote-as 65000
neighbor 2.2.2.2 update-source Loopback0
neighbor 6.6.6.6 remote-as 65000
neighbor 6.6.6.6 update-source Loopback0
!
address-family ipv4
neighbor 2.2.2.2 activate
neighbor 2.2.2.2 route-reflector-client
neighbor 2.2.2.2 next-hop-self all
neighbor 2.2.2.2 send-label
neighbor 6.6.6.6 activate
neighbor 6.6.6.6 route-reflector-client
neighbor 6.6.6.6 next-hop-self all
neighbor 6.6.6.6 send-label
exit-address-family
If we begin by looking at our IGP configs. This is an ASBR due to the fact that we border between two IGP domains – OSPF and ISIS. Note that in this example, there is no need to redistribute between the two, but had we run OSPF in both domains using separate processes, we would have had to redistribute the loopback between the two, because you can only enable an interface for one routing process at a time.
With the above example, I’ve simply advertising loopback0 into both OSPF and ISIS making it possible to both R2 and R6 to reach R4 which ultimately provides full reachability between our PE (along with all the other stuff in BGP, too, obviously).
The other stuff in BGP is the things that happen in our ipv4 address-family. Again we see configuration that isn’t used in regular MPLS VPN configurations. To be precise we have the RR configuration along with the NHS all config. The ‘all’ keyword is necessary because we’re using iBGP where the NH isn’t supposed to be changed. Taking directly from a CIsco command reference:
"(Optional) Specifies that the next hop of both eBGP- and iBGP-learned routes is updated by the route reflector (RR)."
Verification
If we traceroute from R1 to R7, let’s see which labels are being used:
R1#traceroute 7.7.7.7 so lo0
Type escape sequence to abort.
Tracing the route to 7.7.7.7
VRF info: (vrf in name/id, vrf out name/id)
1 10.0.12.2 2 msec 1 msec 1 msec
2 10.0.23.3 [MPLS: Labels 301/405/603 Exp 0] 3 msec 2 msec 2 msec
3 10.0.34.4 [MPLS: Labels 405/603 Exp 0] 2 msec 2 msec 2 msec
4 10.0.45.5 [MPLS: Labels 500/603 Exp 0] 7 msec 11 msec 16 msec
5 10.0.67.6 [MPLS: Label 603 Exp 0] 2 msec 2 msec 2 msec
6 10.0.67.7 6 msec * 2 msec
R1#
So first hop is the client facing interface of our ingress PE, R2. Nothing special here, just IPv4 unicast.
Next we land on our P router, R3. here we see a label stack of three labels! With regular MPLS VPNs we only have 2 labels in our stack when traversing the SP core. I’ve also done a wireshark capture on Gi1.23 of R2:
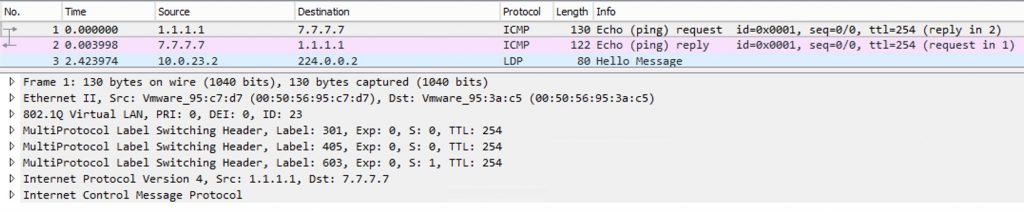
Sure enough the same labels as we see in our traceroute are present in the ping. But why do we impose three labels on R2? Let’s have a look:
R2#sh ip cef vrf a 7.7.7.7/32 detail
7.7.7.7/32, epoch 0, flags [rib defined all labels]
recursive via 6.6.6.6 label 603
recursive via 4.4.4.4 label 405
nexthop 10.0.23.3 GigabitEthernet1.23 label 301-(local:204)
R2#
Now the term hierarchical MPLS starts to make sense. So we start by putting label 603 into the stack. This is our VPN label that should be received from R6 via BGP VPNv4. Let’s double check:
R2#sh bgp vpnv4 u vrf a 7.7.7.7/32
BGP routing table entry for 2.2.2.2:10:7.7.7.7/32, version 8
Paths: (1 available, best #1, table a)
Advertised to update-groups:
2
Refresh Epoch 1
65007, imported path from 6.6.6.6:10:7.7.7.7/32 (global)
6.6.6.6 (metric 3) (via default) from 6.6.6.6 (6.6.6.6)
Origin IGP, metric 0, localpref 100, valid, internal, best
Extended Community: RT:65000:10
mpls labels in/out nolabel/603
rx pathid: 0, tx pathid: 0x0
R2#
Sure enough we have an out label of 603 received from 6.6.6.6, R6. Great! The next label that R2 imposes is 405. We have this extra label due to the fact that R4 changes NH to self for 6.6.6.6/32. This means that we get an extra LSP endpoint, R4, on our way to R6. Hence we must have a label for the path.
Finally we push label 301 to be able to reach R4. This label gets pop’ed by R3 because of PHP before landing on R4 which is what we see at hop 3 (R4) in our traceroute. From here the labels for 6.6.6.6/32 are just swapped until we reach our final destination, the egress PE, R6.
If we had had another IGP domain between OSPF and ISIS, a label stack of 3 would also be imposed by the ASBR, because we’d have a BGP IPv4+label here too, just like we saw on R2.
Legacy
Although unified MPLS makes it possible for an SP to build huge networks, it is an old way of scaling the network. Segment Routing has shown up to replace the way of using MPLS in a very scalable way. I’ll write a post about SR another time. For now, I hope the above post about unified MPLS was worth the read. Thanks!